We are on the cusp of a complete overhaul of the way in which we interact with online content, and I think you should be a hell of a lot more excited than you currently are. Bookmarklet apps like Instapaper, Svpply, and Readability are pointing us toward a future in which content is no longer entrenched in websites, but floats in orbit around users. This transformation of our relationship with content will force us to rethink existing reputation, distribution, and monetization models—and all for the better.
Content today#section2
Most online content today is stuck. It has roots firmly planted in one of the many sites and applications around the web. Because content is rooted, we are forced to spend precious time recording its location in the hopes of navigating back. We bookmark websites. We favorite tweets. We create lists in text files.
In this system, the sites are the gravitational center and we, the users, orbit them, reaching out for a connection whenever we want to interact with the content. This is a fine system, but as users spend more time on consumption-oriented devices like iPads and mobile phones, new demands are being put on content.
Websites have responded quickly to these new demands. Media queries and the responsive design movement have enabled designers to tailor the experience of a site to whichever device a user happens to be using. Flexibility at this macro level of the site is important, but the real breakthroughs will come when we enable the same flexibility at the micro level with individual pieces of content.
Publishers have had the ability to make their content flexible for over a decade. RSS makes it easy to share content feeds with subscribers, saving them the trouble of constantly checking back in. Recently, a series of bookmarklet apps have been slowly transferring the responsibility of making content flexible from the publisher to the user. Leading the charge of this transfer is Instapaper, which has garnered a great deal of praise for doing something called “content shifting.”
Content shifting#section3
…I am certain people want to shift content from discovery oriented devices (laptop, satellite radio, etc.) to consumption oriented devices (tablet, sonos, etc.), and I am certain that we will see this get easier and easier in the coming years.
Content shifting allows a user to take a piece of content that they’ve identified in one context and make it available in another. Perhaps the most popular content shifter is Instapaper, which allows users to easily shift interesting articles they find on the web. With one click of the “Read Later” bookmarklet, the desired article is shifted from a user’s web browser to their mobile device.
Calling Instapaper a content shifter tells only half the story. It puts too much attention on the shifting and not enough on what needs to happen before a piece of content can be shifted. Before content can be shifted, it must be correctly identified, uprooted from its source, and tied to a user. This process, which I call “content liberation” is the common ground between Instapaper, Svpply, Readability, Zootool, and other bookmarklet apps. Content shifting, as powerful as it is, is just the beginning of what’s possible when content is liberated.
Content liberation#section4
Content liberation is a two-part process that results in a piece of content uprooted from its original context and tied to a user. It works like this:
- Distillation: First, the content is stripped down to its raw essence. That essence could be an article, a tweet, a recipe, even a full webpage. What matters is that you end up with all wheat and no chaff. Distilled content is not, however, without attribution. The content never forgets where it is from and neither do you.
- Association: After distillation, the raw content is free-floating and in need of a new home. This is done by tying that content to a user. The typical approach is to have a user account or a desktop folder where the content can reside.
The result of this process is a carbon copy of the purest form of the original content. This liberated copy is tied to a user and its fate is in their hands. If the original site takes the content down or changes it, the liberated copy is unaffected. As users build up collections of this liberated content, they are laying the foundation upon which apps can build their communities and implement their features.
Content collections#section5
Content collections are becoming an increasingly essential data type. They open the door for developers to build apps that are custom-tailored to users’ specific needs. Svpply, for example, enables users to build collections of products they love. Now when I go window-shopping, the windows are all curated by my friends and the taste-makers that I respect.
There are many types of data on the web, but only a few of them have apps designed to help us collect them. I expect this to quickly change. New apps will surface to unlock the potential of recipes, guitar tabs, fonts, travel tips, and more, by enabling users to organize them into collections. Building these content collections is going to be a big deal in the very near future. Consider yourself warned.
Content control#section6
There are two looming issues for liberated content collections—who should control the collections, and who really owns the content inside them? I’m going to tackle the issue of control now, but fear not, I will address ownership soon.
In our discussion of control, let’s examine Instapaper. Do you control that collection of articles? Not really. If another application comes along and offers to print your collection and bind those articles into a book, you have to ask Instapaper for permission to do so. Instapaper helped you build your collection so it becomes a middleman between you and anyone else who can make the collection useful. If Instapaper’s API is lacking in some way (or absent as it was until recently) there’s nothing you can do about it—which is disappointing when you consider all of the effort you put in to building the collection.
Even with a great API in place, this is a fundamentally indirect and inefficient way to deal with content. It’s like you’re surrounding yourself with an entourage of apps and anyone wanting to approach you has to go through them first. Instead of surrounding yourself with applications, why not surround yourself with content?
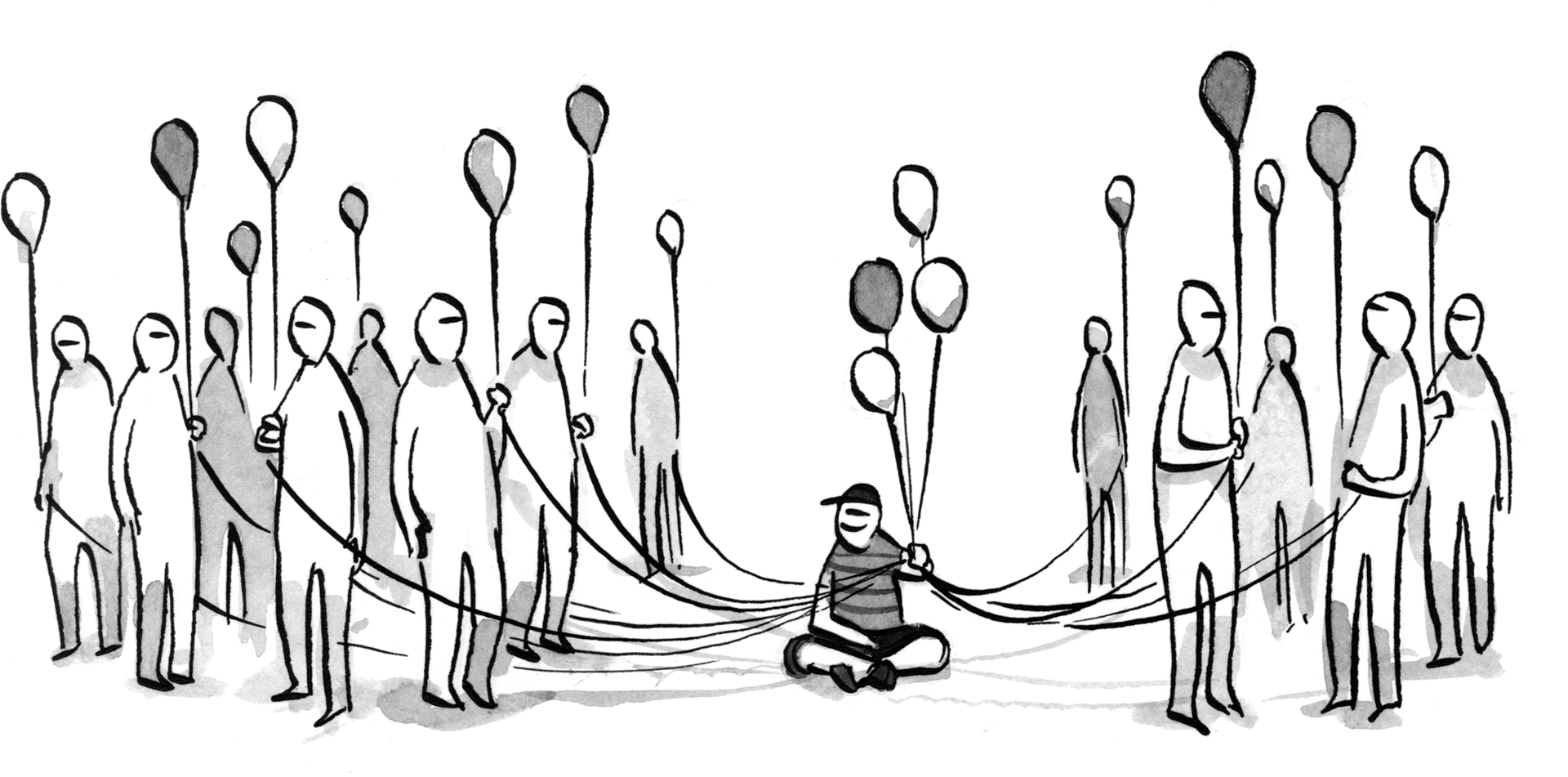
Orbital content#section7
Our transformed relationship with content is one in which individual users are the gravitational center and content floats in orbit around them. This “orbital content,” built up by the user, has the following two characteristics:
- Liberated: The content was either created by you or has been distilled and associated with you so it is both pure and personal.
- Open: You collected it so you control it. There are no middlemen apps in the way. When an application wants to offer you some cool service, it now requests access to the API of you instead of the various APIs of your entourage. This is what makes it so useful. It can be shared with countless apps and flow seamlessly between contexts.
The result is a user-controlled collection of content that is free (as in speech), distilled, open, personal, and—most importantly—useful. You do the work to assemble a collection of content from disparate sources, and apps do the work to make those collections useful. These orbital collections will push users to be more self-reliant and applications to be more innovative.
The API of you#section8
In the traditional business model, consumers vote with their dollars. If they like something, they buy it. If not, they don’t. In the orbital content model, users vote with their content. If an app offers something interesting, they’ll share their content with it. If not, they won’t. Because the content is in orbit around the users, they directly determine who has access to it. Applications will no longer ask for our credentials to other services; instead, they will ask you directly to lend them the content they want to make useful.
This puts an exciting burden on applications to continue to innovate and meet your changing user needs. If an app starts slacking, you can share your content with another app that offers to do something more. For example, I have a tremendous amount of music data built up on Last.fm, but instead of motivating them to innovate, controlling my data allows them to comfortably stagnate. If I could share my Last.fm data with Pandora, or Rdio, or Grooveshark, Last.fm would need to innovate to keep my attention; if they didn’t, those other apps could rise to the occasion by creating new and exciting functionality. Either way, users win.
Content ownership#section9
At this point, I imagine there are quite a few disgruntled readers out there who aren’t happy with the fact that I’ve yet to address the copyright issues associated with orbital content. When content created by others is liberated, some tricky ownership issues come into play.
Many publishers will ask—and it is a fair and familiar question—why should users have the right to carbon copy my content and share it in other contexts? It is a question that belies a concern about something slightly different: compensation. If publishers were compensated $10 every time content was shared and $1 every time it was read on their site, they would do everything in their power to get their content shared. Copying is not the problem—compensation is. Today’s web environment makes it nothing less than a struggle to support content creators. We have unlimited tools for sharing and virtually none for payment.
Let’s look at the movement toward orbital content as an opportunity to rethink compensation. There is a great deal we can do to shape it into something that enriches the web for content creators and content consumers. A major key to this joint enrichment is attribution.
Content attribution and monetization#section10
Attribution is authorship metadata that is bound to content. No matter how far and wide a piece of content spreads, it never forgets who created it and where it’s from. Despite its importance, web attribution is already in shambles. A quick review of Tumblr blogs or the image stream at FFFFound! will show just how difficult it is to find the original sources for most content. This lack of attribution means that content creators receive neither financial nor reputational gains when others spread their work. As good citizens of the web, we have to be vigilant in retaining authorship as we liberate and share content.
If we can keep attribution firmly in place, content collections and orbital content offer publishers new opportunities for both financial and reputational gain. Traditionally, site owners monetize their content by generating traffic to get as many “eyeballs” in front of their advertisements as possible. Strict content attribution allows us to take an interesting twist on this model. We can push the notion of eyeballs to include anyone who sees your content in any context so long as it is clear that you are its creator. If attribution can travel with content, why not monetization? RSS feeds have set some precedent for ads following content into other contexts. We can push this model further by enabling ads to travel alongside individual pieces of content and enabling content creators to be compensated whether that content is viewed on their site or somewhere else on the web.
Attributed orbital content can be a conduit for communication between the content creator and various content consumers. At my company, Fictive Kin, we are obsessed with “Haters Gonna Hate,” an animated gif created by These Are Things. That gif quickly became a bona fide internet meme and was seen by millions of people, many of whom saved and reblogged it. Later, These are Things released haters gonna hate t-shirts and letterpress prints to capitalize on the success of their creation. With orbital content and strict attribution, it would be easy to give them the ability to advertise the prints and shirts to anyone who had collected their original gif and let them know there were new ways to show off their love.
Content applications#section11
The things that we like define us as much as the people we know. Content liberation, orbital content, and attribution are enabling a new class of applications that are built on top of our content and our interests instead of our social graphs. We can look to Instapaper, Svpply, and other bookmarklet apps for the beginnings of this movement.
These initial apps hint at some possible paths, but we should remember orbital content is still a wide open frontier and we are free to shape it as we please. If we get a good jump on it, we can create a web in which content creators are rewarded fairly, content consumers are given unprecedented power, and web applications are pushed to constantly innovate and improve themselves. Not too shabby.
Sorry to bring this up, but “custom-tailored” is tautological.
Otherwise, very interesting article, thanks!
Because I can, just to prove your point. 😉 Thanks for the great content. 🙂
I’d love to see the W3C or some other group work toward a common practice that might even become a spec for locking elements together for attribution. This would allow applications like “Gimme Bar”:http://gimmebar.com to collect articles, images, music, etc that’s readily available on the web, but keep the context meaningfully. It could work like a microformat:
… content …
Everything that’s between the containers (choose your own name and don’t gripe about my convention please) gets pulled into the apps that utilize this tech. This gives compensation data points so that it can trace where things come from and go and offers people more opportunity to grow their reputations, brands, and add cash to their wallets.
More cash = better beer, everywhere. This is a good thing.
Press on Mr. Koczon, well written, well thought out.
bq. Sorry to bring this up, but “custom-tailored” is tautological.
You’re not only right, you’re correct. 😉 We should have caught that in editing.
@skilldrick – I loves me some tautology.
@Jaronoff – Well met, sir. That said, maybe Readability is a step closer to where we should be headed? Get these A List Apart folks some money.
@squaredeye – I didn’t think anyone would spot the connection between the future of content and the general improvement of the quality of beer. Bravo.
Absolutely love the idea of a personal API that keeps all my data/content in one place and allows services to interact with it, rather than the services holding my data/content and forcing me to interact with them to get to it.
I’ve no idea how it could be done technologically (perhaps hosted on your personal site), but to truly _own_ my data—photos, messages, articles I’ve read, scrobble data, things I’ve liked, etc etc,—and then be able to use whichever interface I choose to interact with that data (flickr, facebook, twitter, spotify, last.fm, etc etc) would be a dream come true. It would be like being able to choose whether to edit a JPG in Photoshop or Fireworks… I’d love to have that same freedom with all my online data.
Very excited by this article; I love the idea of an attribution standard that could flow along with content across the web. No more watermarking of photos?! Appropriate support for content creators? Sign me up.
(Fun thought: If we could actually trace the origin and propagation of content across the web, the term “internet registrar” would take on a whole new meaning. Closer to gallery registrar — the person who tracks the path of each artwork, and ensures its authenticity.)
Looking forward to seeing the APIs this article inspires…
bq. If we can keep attribution firmly in place…
That’s a pretty huge “if”. I’d like to hear more about how this might be made to work. Are you thinking pay/login walls? HTML spec changes? Honesty of the anonymous content consumer?
Great read, Cameron & great comments. I’m particularly digging (perhaps not surprisingly as someone involved in the Readability project) the angle you’re taking about attribution as a potential source for monetization. How in an ideal world, the further the reach of my content and ideas, the more I might directly benefit.
As is usually the case for me, your comments evoked a passage from Jaron Lanier’s ‘You Are Not A Gadget’, in it (pages 69-70) he writes:
bq. Nelson’s ambitions for the economics of linking were more profound than those in vogue today. He proposed that instead of copying digital media, we should effectively keep only one copy of each cultural expression—as with a book or a song—and pay the author of that expression a small, affordable amount whenever it is accessed. [..] As a result, anyone might be able to get rich from creative work. The people who make a momentarily popular prank video clip might earn a lot of money in a single day, but an obscure scholar might eventually earn as much over many years as her work is repeatedly referenced. [..] Someday I hope there will be a genuinely universal system along the lines proposed by Nelson. I believe most people would embrace a social contract in which bits have value instead of being free. Everyone would have easy access to everyone else’s creative bits at reasonable prices—and everyone would get paid for their bits. This arrangement would celebrate personhood in full, because personal expression would be valued.
…here’s to hoping we get there, and perhaps even via more direct means of compensation versus my ads following my content around the web.
Ted Nelson, who invented Hypertext, has been going on about something very similar to this concept for years: he calls it Project Xanadu. Sir Tim Berners Lee came up with HTML and the web we know now, but Nelson’s vision was quite different, and never fully realised. Perhaps this prophesied transition to orbital content will finally fulfil this rival web founder’s vision?
Already it’s HTML5 that really frees up the web for Orbital Content with the new
And Sir Tim was way off with HTML5, in that it’s the WHATWG under Ian Hickson rather than Sir Tim’s W3C that developed and is developing the HTML5 spec.
Ted Nelson talks about monetizing content. Sir Tim never did. Nelson is also particularly fervent about the need to preserve attribution.
So how would we use HTML5 to monetise content and preserve atribution?
The key would be to make liberated content impossible to edit. This will be difficult; it’s an open source web… people will. But the content’s integrity must be maintained in any given context it finds itself. If each
@Timothy & @Ali – Ted Nelson is a huge inspiration. Been trying to track down some of his older works because I’m tired of seeing him quoted without knowing the whole deal.
@Timothy – There is no end to the praise I hear about Lanier’s book. You pushed me over the edge and I finally just bought it. If you haven’t yet read it, I recommend you pick up “Glut”:http://www.amazon.com/gp/product/0801475090/ by Alex Wright. I love this book and it is a great study of information throughout history. Lots of bits about Nelson and other like-minded folks.
@Ali – I’m not sure you can force the attribution issue by making liberated content impossible to edit. There are just too many ways around that. I think we could probably get further with some combination of creating established norms / etiquette and making content more interesting and valuable if attribution is in place. I think that especially in the case of the latter, this will be very powerful. I also tend to think that people want attribution. They want to know who created the things they love.
Isn’t PDF an example of a content format that’s currently available, intended for publication, with a degree of attribution and which is relatively difficult to copy.
And what about the EXIF and IPTC data in images? Although easy top circumvent, they could be made, at least in part, lockable.
@Timothy & @Ali – Ted Nelson is a huge inspiration. Been trying to track down some of his older works because I’m tired of seeing him quoted without knowing the whole deal.
@Timothy – There is no end to the praise I hear about Lanier’s book. You pushed me over the edge and I finally just bought it. If you haven’t yet read it, I recommend you pick up “Glut: Mastering Information Through the Ages by Alex Wright. I love this book and it is a great study of information throughout history. Lots of bits about Nelson and other like-minded folks.
@Ali – I’m not sure you can force the attribution issue by making liberated content impossible to edit. There are just too many ways around that. I think we could probably get further with some combination of creating established norms / etiquette and making content more interesting and valuable if attribution is in place. I think that especially in the case of the latter, this will be very powerful. I also tend to think that people want attribution. They want to know who created the things they love.
As a content professional—web writer, editor, mediocre photographer and videographer—I’m wondering how such a move toward content clouds/orbits will change our discipline.
What new skills or perspectives should we be thinking about? How will we approach content development and strategy differently? Measurement and analytics?
Sure, it will remain essential to “simply” produce good, useful, intelligent content, but how else can the content professional community support positive trends in consumption?
As much as I like Instapaper and similar services, they’re nothing more than a glorified microfilm. Content is meant to work with its context (its medium and presentation are a big factor in how/what I read) and if everything is cookie-cut into the same layout then you not only lose part of your branding, but also you lose personality attached to the article.
Great article and very thought-provoking. But while attribution and monetization are, indeed, critical to this concept’s success, there’s one other component that needs to be in place for many types of content – the ability for the original author to update it or trigger “global” changes to it.
Where Nelson got it “right” was the concept of sole-sourcing content, so that an author could retain control over that content over time. If a mistake were found or a new insight reached, the content could change and all references to it would be automatically updated.
Without that capability, authors of “ephemera” have a significant disincentive to share their content, as they would be simply proliferating clouds of “semi-finished” or possibly erroneous work.
As an example – I as a user might have a story about a kidnapped person that interests me. I put that into my orbit, but unless the author can auto-update it, I will never find out whether the person is found. The value lies in being able to have the topic itself orbit me, with all updates to the article (and any related articles I choose) automatically flowing in without my having to go seek them.
First, great post and great concept.
Although the copyright issue is a huge one, the applications this could spur are endless. However, are content creators – big and small – willing to change the game or stay with the devil that they know? For example, I’m in the radio industry where we still measure value based on potential reach offline and overall visits to our sites online. Attribution is huge in that respect. We need credit in order to prove our worth in this outdated model. Any desire to change this has been met with fear and on-with-the-buggy-whip mentality.
Of course, if some kind of standards are adopted, uncertainty will fester in the beginning. The questions will be many and the answers will be sometimes contradictory. Should this be in the form of individual services or an overall adopted standard? Should content creators be part of organized pipelines of networks or individual contractors who serve as their own agents to get their works exposed? Maybe both? Maybe neither and a new paradigm is developed.
I have a lot of questions but I don’t think the answers will be too hard to come by.
I’m wondering if the Facebook “like” button and the Open Graph protocol may be at least partially pointing the way forward. I don’t mean literally the “like” button – I don’t think the future of content should really in in the hands of any company – that would be pretty much the opposite of what this article was about. But the idea of the like button, where you are essentially subscribing to a piece of content, could play a part. And the Open Graph protocol is not owned by Facebook, even if they are the most prominent consumers of it. There’s nothing stopping other services from also making use of the Open Graph, and if they were to do so, then Facebook or any other service would simply be one of these applications consuming content.
What if there were some client-based mechanism – say a bookmarklet or some such – that allowed you to “like” or “subscribe” to a piece of content. This might create a registry on the client side (maybe in the browser), which whenever the user had an internet connection would check all of the “liked” sites to see if the content had updated. Other apps and services could also query a user’s local registry and offer to do stuff with the liked content. It would be similar to the little RSS “subscribe” buttons, I suppose, but not restricted to XML.
I’m not sure that gets us all the way to users controlling their data, though. If I like a webpage that then goes down, I lose access to it. Still, it would be a step forward from where we are now.
@dan – This is a very tough question. I am not sure I know the answer. One thing I’ve always wished is that creators of images would title their images with a bit more metadata about themselves. This is pretty easily scrubbed away though. Amazon S3 does so as a byproduct of storing the image on their servers. At this point, maybe the most important thing a content creator can do is be willing to experiment. Don’t harden against new opportunities. I don’t think you’ll have to wait long for folks to come knocking at your door to help you liberate and monetize your content. I’ll consider this some more, but that’s what I got for now.
@mven – I don’t think it is a stretch to say that the majority of content creators (i.e. photographers, illustrators, writers) are not masters of the web context. They were not trained in web design or UX or IA. While I agree that content is meant to work with its context, I see no reason why the quality of my context should be limited by the technical prowess or imagination of the content creator. Instapaper is a reaction to the overly burdensome contexts that abound on the web. It simplifies and by doing so relieves a great deal of the strain associated with viewing context. That said, it is just one context option. It won’t be long before someone creates an “Instapaper” that liberates articles and presents them in a comic sans context. I’m just not sure the microfilm analogy works that well.
@kgoeller – I think auto-updating content will be just one more data type that will float in your personal orbit. Storytelling like the kind you described is something we’ve yet to see a great deal of, but I expect that will change. Bringing a topic into your orbit is a very powerful concept. I don’t, however, think that works as well with a photograph or a recipe, for example. You may think it is unfinished but for me it is perfect. If you changed it, I would lose the thing I had saved. If you retained control, you could also delete it. It’s a bit too reminiscent of the Kindle / 1984 controversy.
@kdwilliams – I really don’t think content creators have too much say in the matter. The reality is that this is already happening, but in back channels. People are saving your recipes in text files or they are downloading images / videos / music to folders on desktops. They are sharing on Dropbox or through Gmail. Content creators have no idea how much activity is happening around their content. As services arise to give them insight into that, I think they’re interest will be sufficiently piqued. When ways to monetize that activity become more apparent, I think they’ll be fairly happy pandas.
@Philip – I’m in agreement with most of what you’re saying, but I’d substitute “save” for “subscribe”. Subscribe leaves the content behind and requires another service to keep the list going of your subscriptions. Save truly brings the content into your orbit where it can exist safe and sound.
Cameron,
Really enjoyed the article— you presented some disruptive ideas about web content that I never considered, it made for a great read.
Things got very interesting for me when you starting talking about the issues of content attribution, ownership, and compensation. I am the co-founder of “TipTheWeb”:http://tiptheweb.org/ which is addressing those exact things! Your article inspired me to reply on our blog: “Orbital Content — The Missing Pieces”:http://blog.tiptheweb.org/post/4767694224/orbital-content-the-missing-pieces
It would be excellent to keep this discussion going, and I’m curious if you also think TipTheWeb has a place to help fill-in the attribution and compensation side of your orbital content ideas?
As expected, a very interesting article and discussion… I’m always happy when I see new stuff from ALA.
Thus far most of the comments here are discussing the attribution issue (which I find a fascinating and difficult problem), but I’d like to see a bit more chatter about the first part which terminates with proposing an “API of You” to mediate the communication between services and the orbital data that falls under individual purview.
As lovely as the term is, however, the technical details of such a thing are far from obvious to me, and I’m curious to get some expansion on what this might look like. First, I’ll note that the term content as used here seems to be encompassing what I see as really 3 types of data, namely
1. Personal information – name, email, date of birth, physical location, etc.
2. Personally authored content – blog posts, emails, tweets, status updates
3. Personally aggregated content – collected articles, links, text or code snippets and so forth.
There’s likely some overlap here in the sense that tweets and other Facebook-type updates could blend into both 1 and 3, but I think it’s useful to think about them distinctly. Also, it seems to me there’s actually a fourth category that I neglected to include because while it’s currently separate, the article argues for it being included into the third segment, I think. That is, data that is (or could be) generated as a byproduct of using the rest… play counts for your music library, statistics about site visitation, how long you spend using various apps, who you most frequently retweet, and so on.
These are data that are generated by many of the apps we use, but as stated, are locked away in the database for that specific application. Freeing this, and giving individuals the ability to share or not share it as they see fit and perhaps more critically, consolidating it — merging my listening data from last.fm, pandora, my iPhone, iTunes at home, … — is a noble goal, certainly, but devilishly complex.
First you must also have common data formats for any and all content that you’re storing, and get everyone to use them which is never a trivial matter, and multiplied by the vast number of different data types you could conceive of. Some of these we have and some are relatively trivial technically, but adoption becomes a stumbling block.
And so, finally, what is this API of You, exactly? Since I’m not a computer (nor a gadget), there must be an application that stores, classifies (or allows me to classify) and mediates these disparate bits of data, and provide the common interface for sharing it around to other applications that want to make use of the information and collecting it from applications that generate new stuff.
Beyond what’s been mentioned already, I think the folks at Diaspora are working towards a practical solution for some of this, at least for some subset of the relevant data, so maybe that’s our starting point?
My understanding of distilled content is just the article. How do you reconcile sending ads along with the liberated content if I as a user just want the pared down text? Do you envisage text only ads?
Great to hear (see?) thought-provoking ideas on revenue generation, as well as the social/tech advancements
And here I was wondering, “Is anyone out there thinking about how content strategy should apply to mobile? If so, who?” Meanwhile, you’re writing this article, which is several steps ahead of the concept of “mobile” in positing what relevant, targeted content might look like in the future.
Kudos.
Thanks for the article. Pretty sweet. I like the idea of an API of me. ITS ALL ABOUT ME. ☺ Seriously though, it is about the user.
I love to think about this in the context of social graphs and how I think this can really refine them. Most services make the assumption that people are nodes, and “friendships”, “follows”, “content” etc. are the link between them. I disagree with this notion. I see content and products as nodes, and users as the link between them.
Content is created to draw our attention. Products are made for us to buy. Once either one is created, its identity is cemented. The next step involves users deciding whether or not to consume the content or buy the product. But we all know as users, we are mercurial by nature in choosing the content we consume and the products we buy. Content Creators and product manufacturers act, then users and consumers react.
I see the concept of orbital content as the first step to finally streamlining the cluttered and noisy social graph experience. How do I finally share certain types of content with the people I deem relevant in that topic sphere? By choosing the content I want to orbit around me, and then finding the people (friends, taste makers) I share that content with as a common variable.
For instance, I share cycling content with my cycling buddies, Brooklyn eateries with fellow Brooklyn folks, and very esoteric topics like horsehide leather jackets made from horses that died of natural causes with people who like leather jackets. And there might even be some overlap with some of these interests. My point is, these tools give users the power to surround themselves with the content and users they want. Awesome.
@KBenton – Those are some really great insights into data types, especially the “fourth” type you mentioned. I think in terms of the implementation of an API of you, it won’t actually be the individual users implementing this tech. Someone will come along and offer to do the “API of you” work. The important thing, in my mind, would be ensuring that the content was backed up to something like Dropbox or Amazon cloud storage so that if you want to switch API of you providers, you can do so easily.
@LibertyBasil – I really don’t know the layout of ads in specific contexts. I’m more hoping for some give and take between content creators and consumers. Creators will bring more relevant ads and get on board with a more liberal use of their content. Content consumers will be willing to take on ads
@Al Dente – Thanks you, sir.
@Melanie – Thank you so much. Very nice of you to say.
@krluna – Social graphs are ripe for this sort of relationship. Excellent comment. I don’t have much to add other than that I think Diaspora is trying for this.
If we’re imagining worlds, why not a step further into a world where compensation for content consumption makes advertisers redundant.
Businesses need no longer monetize with ads chasing content when content could become the creative capital of our businesses.
Can someone help point out the flaws in _that_ future?
Thanks Cameron, what a good read. I’ve been thinking about the evolution of handling content in a very similar way as you describe and envision, and I’m quite surprised to read that the shift is already started. It’s fascinating, and huge!
The problematic my thinking revolves around is mostly about filtering content. How to filter user-tailored content before it is assessed by the user? Social network oriented solutions are unsatisfactory: I share some interests and opinions with my friends and networks, but only partially; and most importantly, I want to tap into the entire web, not just my networks – it’s the power of the web!
Linear voted content a la Reddit is not much better. As Paul Graham explains, it strongly favors easy-to-read content that get more votes.
Do you or anyone have ay insight into this issue? Or do you guys know anybody who has tackled this question with some success?
Cameron,
I really enjoyed your article, and am enthusiastic about what is beginning to take shape around content right now: a focus on preserving reader attention, portability, and responsiveness to context, especially as these ideas have been handled by you, Mandy Brown, Jeffrey Zeldman, and others. It’s important that those who enthusiastically and prolifically produce content lead the way.
I’m curious about something you mentioned early on in this piece: “Flexibility at this macro level of the site is important, but the real breakthroughs will come when we enable the same flexibility at the micro level with individual pieces of content.” I’m with you, for sure, in terms of how web design needs to adapt to be flexible (i.e. device agnostic). But I wonder about the design implications of apps like Readability and Instapaper, etc. I love these tools, again, because they provide a courtesy to readers like me–enabling me to focus my attention in a quiet space free of visual distractions and other promotional intrusions–but also can anticipate the anxiety they might create for designers.
I just sent off my next column to the Print magazine editors–it’s going to be about what I called “Post-Desk Content” (we’ll see if that title makes it)–and was following a similar line of questioning: If content is not its container (i.e. a book, article, movie, etc. has a substance that is something other than it’s form) then does it have an inherent design? If content has no inherent design, what then, for designers? I ended up talking more about the anachronistic design metaphors we tend toward when designing modern content containers (interfaces, mostly)–the jukeboxes, shelves, etc., but I’d love to hear what people are thinking about how content liberation and design interact.
Thanks for a thoughtful piece,
CB
“The key would be to make liberated content impossible to edit.”
Not impossible to edit as that is probably impossible but what about something like the checksum that is used to check errors in transmitted data.
Would it be possible to realise something of that effect in html5 so that the liberated content itself could indicate it was the authentic and true original? Like a self checking digital signature.
I’ve noticed that there is a push in the forums I visit to try and credit the original of any item. That is, to take the trouble not to link to sites that repeat all, or parts of the original but to track the original down and link directly to that instead.
I’d hope that the same would come to apply to liberated content. The only trick then is to implement methods of payment as quoted above from Jaron Lanier where authors of original creative content could gain a reasonable return over the long term.
Really interesting article, very excited about the progression of the web, and can’t wait to try this out.
There is nothing worse than saving a link, or following one, only to find that it has been shut down and lost forever.
I suppose it’s almost like keeping an online diary of where you have been and the interesting things you have found along the way.
@chrbutler – I am going to channel two of my design heroes, Robert Bringhurst and Ladislav Sutnar, for my response to your comment. Good design should “honor content” and “intensify comprehension.” Poor design serves as a simple “wrapper” as you put it, but I believe that design done well becomes fused with the content to such an extent that few would want to separate the two. Removing design cheapens the content. Instapaper / Readability are a reaction to the fact that much web design is garbage and most content is better off without it. If everything plays out as I hope, it will be interesting for designers to see which of their design work is actively discarded by users and which is preserved.
@A Scott – I think this is a much bigger problem than it seems at first. If two people purport to be the creators of the same piece of content, how would you determine ownership? Is there some new registry or governing body that determines a content originator and enforces the checksum for it? There don’t really seem to be practical options. The change needs to be cultural. It should be significantly looked down upon to scrub or change attribution. I believe that will cover the 80% case, which is enough to change the web.
@Stephanie93 – Thanks Stephanie. My very biased guess says that you won’t have to wait very long for products to address these ideas.
Useful insights to a complex question. It is a very disconcerting to web publishers, but it is a reality – online content is immediately sharable. Personally, my view as I experiment with online publishing is to embrace this reality. This article begins to tease out the options on how to create a viable publication in the environment. The answer however remains distant, and the only way to get closer to this, is through experimentation. Thanks for an insightful article.
Thanks for the great article about content. 🙂 it’s really interestly
I’m a big fan of Instapaper – as I dig my way through tweets with url links to articles I throw them straight into to instapaper. I find the content so much easier to read as a result of this.
In terms of using the app as a way of collecting for later use – I just use it as a temporary reading platform.
Superb article! 🙂