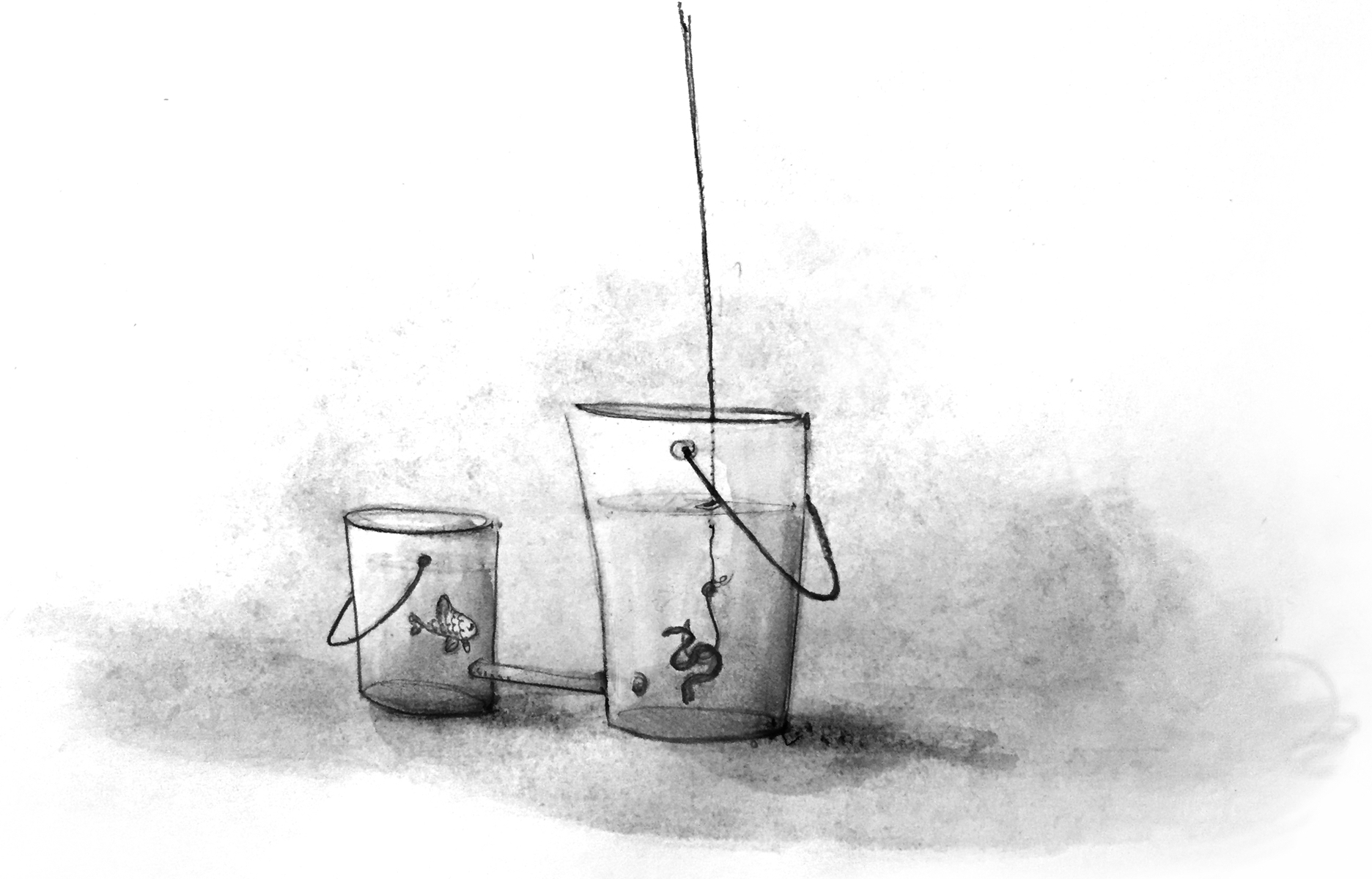
As any developer who works with other developers can attest, if code is unclear, problems occur. In Part I of this series, I went over some principles to improve clarity in our code to prevent problems that can arise from unclear code. As our apps get larger, clarity becomes even more important, and we need to take extra care to ensure that our code is easy to read, understand, and modify or extend. This article discusses some more-advanced principles related to object-oriented programming (OOP) to improve clarity in larger apps.
Note: Though the principles in this article are applicable to a variety of programming languages, the examples pull from object-oriented JavaScript. If you’re not familiar with this, read my first article to get up to speed, as well as to find some other resources to help improve your understanding of object-oriented programming.
The Law of Demeter#section2
Imagine you’re an office manager at an apartment complex. The end of the month comes and the rent is due. You go through the drop box in the office and find checks from most of your tenants. But among the neatly-folded checks is a messy note on a scrap of paper that instructs you to unlock apartment 309, open the top drawer of the dresser on the left side of the bed, and remove the money from the tenant’s wallet. Oh, and don’t let the cat out! If you’re thinking that’s ridiculous, yeah, you’re right. To get the rent money each month, you shouldn’t be required to know how a tenant lays out their apartment and where they store their wallet. It’s just as ridiculous when we write our code this way.
The Law of Demeter, or principle of least knowledge, states that a unit of code should require only limited knowledge of other code units and should only talk to close friends. In other words, your class should not have to reach several levels deep into another class to accomplish what it needs to. Instead, classes should provide abstractions to make any of its internal data available to the rest of the application.
(Note: the Law of Demeter is a specific application of loose coupling, which I talk about in my first article.)
As an example, let’s say we have a class for a department in your office. It includes various bits of information, including a manager. Now, let’s say we have another bit of code that wants to email one of these managers. Without the Law of Demeter, here’s how that function might look:
function emailManager(department) {
const managerFirstName = department.manager.firstName;
const managerLastName = department.manager.lastName;
const managerFullName = `${managerFirstName} ${managerLastName}`;
const managerEmail = department.manager.email;
sendEmail(managerFullName, managerEmail);
}Very tedious! And on top of that, if anything changes with the implementation of the manager in the Department class, there’s a good chance this will break. What we need is a level of abstraction to make this function’s job easier.
We can add this method to our Department class:
getManagerEmailObj: function() {
return {
firstName: this.manager.firstName,
lastName: this.manager.lastName,
fullName: `${this.manager.firstName} ${this.manager.lastName}`,
email: this.manager.email
};
}With that, the first function can be rewritten as this:
function emailManager(department) {
let emailObj = department.getManagerEmailObj();
sendEmail(emailObj.fullName, emailObj.email);
}This not only makes the function much cleaner and easier to understand, but it makes it easier to update the Department class if needed (although that can also be dangerous, as we’ll discuss later). You won’t have to look for every place that tries to access its internal information, you just update the internal method.
Setting up our classes to enforce this can be tricky. It helps to draw a distinction between traditional OOP objects and data structures. Data structures should expose data and contain no behavior. OOP objects should expose behavior and limit access to data. In languages like C, these are separate entities, and you have to explicitly choose one of these types. In JavaScript, the lines are blurred a bit because the object type is used for both.
Here’s a data structure in JavaScript:
let Manager = {
firstName: 'Brandon',
lastName: 'Gregory',
email: 'brandon@myurl.com'
};Note how the data is easily accessible. That’s the whole point. However, if we want to expose behavior, per best practice, we’d want to hide the data using internal variables on a class:
class Manager {
constructor(options) {
let firstName = options.firstName;
let lastName = options.lastName;
this.setFullName = function(newFirstName, newLastName) {
firstName = newFirstName;
lastName = newLastName;
};
this.getFullName = function() {
return `${firstName} ${lastName}`;
}
}
}Now, if you’re thinking that’s unnecessary, you’re correct in this case—there’s not much point to having getters and setters in a simple object like this one. Where getters and setters become important is when internal logic is involved:
class Department {
constructor(options) {
// Some other properties
let Manager = options.Manager;
this.changeManager(NewManager) {
if (checkIfManagerExists(NewManager)) {
Manager = NewManager;
// AJAX call to update Manager in database
}
};
this.getManager {
if (checkIfUserHasClearance()) {
return Manager;
}
}
}
}This is still a small example, but you can see how the getter and setter here are doing more than just obfuscating the data. We can attach logic and validation to these methods that consumers of a Department object shouldn’t have to worry about. And if the logic changes, we can change it on the getter and setter without finding and changing every bit of code that tries to get and set those properties. Even if there’s no internal logic when you’re building your app, there’s no guarantee that you won’t need it later. You don’t have to know what you’ll need in the future, you just have to leave space so you can add it later. Limiting access to data in an object that exposes behavior gives you a buffer to do this in case the need arises later.
As a general rule, if your object exposes behavior, it’s an OOP object, and it should not allow direct access to the data; instead, it should provide methods to access it safely, as in the above example. However, if the point of the object is to expose data, it’s a data structure, and it should not also contain behavior. Mixing these types muddies the water in your code and can lead to some unexpected (and sometimes dangerous) uses of your object’s data, as other functions and methods may not be aware of all of the internal logic needed for interacting with that data.
The interface segregation principle#section3
Imagine you get a new job designing cars for a major manufacturer. Your first task: design a sports car. You immediately sit down and start sketching a car that’s designed to go fast and handle well. The next day, you get a report from management, asking you to turn your sports car into a sporty minivan. Alright, that’s weird, but it’s doable. You sketch out a sporty minivan. The next day, you get another report. Your car now has to function as a boat as well as a car. Ridiculous? Well, yes. There’s no way to design one vehicle that meets the needs of all consumers. Similarly, depending on your app, it can be a bad idea to code one function or method that’s flexible enough to handle everything your app could throw at it.
The interface segregation principle states that no client should be forced to depend on methods it does not use. In simpler terms, if your class has a plethora of methods and only a few of them are used by each user of the object, it makes more sense to break up your object into several more focused objects or interfaces. Similarly, if your function or method contains several branches to behave differently based on what data it receives, that’s a good sign that you need different functions or methods rather than one giant one.
One big warning sign for this is flags that get passed into functions or methods. Flags are Boolean variables that significantly change the behavior of the function if true. Take a look at the following function:
function addPerson(person, isManager) {
if (isManager) {
// add manager
} else {
// add employee
}
}In this case, the function is split up into two different exclusive branches—there’s no way both branches are going to be used, so it makes more sense to break this up into separate functions, since we know if the person is a manager when we call it.
That’s a simplified example. An example closer to the actual definition of the interface segregation principle would be if a module contained numerous methods for dealing with employees and separate methods for dealing with managers. In this case, it makes much more sense to split the manager methods off into a separate module, even if the manager module is a child class of the employee module and shares some of the properties and methods.
Please note: flags are not automatically evil. A flag can be fine if you’re using it to trigger a small optional step while most of the functionality remains the same for both cases. What we want to avoid is using flags to create “clever” code that makes it harder to use, edit, and understand. Complexity can be fine as long as you’re gaining something from it. But if you’re adding complexity and there’s no significant payoff, think about why you’re coding it that way.
Unnecessary dependencies can also happen when developers try to implement features they think they might need in the future. There are a few problems with this. One, there’s a considerable cost to pay now in both development time and testing time for features that won’t be used now—or possibly at all. Two, it’s unlikely that the team will know enough about future requirements to adequately prepare for the future. Things will change, and you probably won’t know how things will change until phase one goes out into production. You should write your functions and methods to be open to extend later, but be careful trying to guess what the future holds for your codebase.
Adhering to the interface segregation principle is definitely a balancing act, as it’s possible to go too far with abstractions and have a ridiculous number of objects and methods. This, ironically, causes the same problem: added complexity without a payoff. There’s no hard rule to keep this in check—it’s going to depend on your app, your data, and your team. But there’s no shame in keeping things simple if making them complex does not help you. In fact, that’s usually the best route to go.
The open/closed principle#section4
Many younger developers don’t remember the days before web standards changed development. (Thanks, Jeffrey Zeldman, for making our lives easier!) It used to be that whenever a new browser was released, it had its own interpretation of things, and developers had to scramble to find out what was different and how it broke all of their websites. There were articles and blog posts written quickly about new browser quirks and how to fix them, and developers had to drop everything to implement those fixes before clients noticed that their websites were broken. For many of the brave veterans of the first browser war, this wasn’t just a nightmare scenario—it was part of our job. As bad as that sounds, it’s easy for our code to do the same thing if we’re not careful about how we modify it.
The open/closed principle states that software entities (classes, modules, functions, etc.) should be open for extension but closed for modification. In other words, your code should be written in such a way that it’s easy to add new functionality while you disallow changing existing functionality. Changing existing functionality is a great way to break your app, often without realizing it. Just like browsers rely on web standards to keep new releases from breaking our sites, your code needs to rely on its own internal standards for consistency to keep your code from breaking in unexpected ways.
Let’s say your codebase has this function:
function getFullName(person) {
return `${person.firstName} ${person.lastName}`;
}A pretty simple function. But then, there’s a new use case where you need just the last name. Under no circumstances should you modify the above function like so:
function getFullName(person) {
return {
firstName: person.firstName,
lastName: person.lastName
};
}That solves your new problem, but it modifies existing functionality and will break every bit of code that was using the old version. Instead, you should extend functionality by creating a new function:
function getLastName(person) {
return person.lastName;
}Or, if we want to make it more flexible:
function getNameObject(person) {
return {
firstName: person.firstName,
lastName: person.lastName
};
}This is a simple example, but it’s easy to see how modifying existing functionality can cause major problems. Even if you’re able to locate every call to your function or method, they all have to be tested—the open/closed principle helps to reduce testing time as well as unexpected errors.
So what does this look like on a larger scale? Let’s say we have a function to grab some data via an XMLHTTPrequest and do something with it:
function request(endpoint, params) {
const xhr = new XMLHttpRequest();
xhr.open('GET', endpoint, true);
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
// Do something with the data
}
};
xhr.send(params);
}
request('https://myapi.com','id=91');That’s great if you’re always going to be doing the same thing with that data. But how many times does that happen? If we do anything else with that data, coding the function that way means we’ll need another function to do almost the same thing.
What would work better would be to code our request function to accept a callback function as an argument:
function request(endpoint, params, callback) {
const xhr = new XMLHttpRequest();
xhr.open('GET', endpoint, true);
xhr.onreadystatechange = function() {
if(xhr.readyState == 4 && xhr.status == 200) {
callback(xhr.responseText);
}
};
xhr.send(params);
}
const defaultAction = function(responseText) {
// Do something with the data
};
const alternateAction = function(responseText) {
// Do something different with the data
};
request('https://myapi.com','id=91',defaultAction);
request('https://myapi.com','id=42',alternateAction);With the function coded this way, it’s much more flexible and useful to us, because it’s easy to add in new functionality without modifying existing functionality. Passing a function as a parameter is one of the most useful tools we have in keeping our code extensible, so keep this one in mind when you’re coding as a way to future-proof your code.
Keeping it clear#section5
Clever code that increases complexity without improving clarity helps nobody. The bigger our apps get, the more clarity matters, and the more we have to plan to make sure our code is clear. Following these guidelines helps improve clarity and reduce overall complexity, leading to fewer bugs, shorter timelines, and happier developers. They should be a consideration for any complex app.
Thanks#section6
A special thanks to Zell Liew of Learn JavaScript for lending his technical oversight to this article. Learn JavaScript is a great resource for moving your JavaScript expertise from beginner to advanced, so it’s worth checking out to further your knowledge!
MAPLE ARCH combines the legacy of two great design practices into an even stronger, more distinct voice that is characterized by the strength of our ideas, the spirit of our culture and the passion of our people to make the world a better place.
http://maplearch.in/
I tried this code, but i couldn’t help it on my website. I am having trouble. please can you take a look. Thanks
http://www.lightthatblunt.org/best-plasma-lighters/