Seventy-one percent of today’s internet users don’t speak English as a first language, and that number keeps growing. But few people specialize in internationalization. As a result, most sites get it wrong—because things that seem straightforward are often anything but.
Take pluralization. Turning singular words into plurals within strings gets tricky quickly—even in English, where most plural words end with an s. For instance, I worked on a photo-sharing app that supported two languages, English and Chinese. It was easy to add an s to display “X like[s]” or “Y comment[s].” But what if we needed to pluralize “foot” or “inch” or “quiz”? Our simple solution became a broken hack.
And English is a relatively simple case. Many languages have more than two plural forms: Arabic, for example, has six, and many Slavic languages have more than three. In fact, at least 39 languages have more than two plural forms. Some languages only have one form, such as Chinese and Japanese, meaning that plural and singular nouns are the same.
How can we make sense of these complex pluralization issues—and solve them in our projects? In this article, I’ll show you some of the most common pluralization problems, and explain how to overcome them.
Problems with pluralization#section2
Pluralization gets even more complex: each language also has its own rules for defining each plural form. A plural rule defines a plural form using a formula that includes a counter. A counter is the number of items you’re trying to pluralize. Say we’re working with “2 rabbits.” The number before the word “rabbits” is the counter. In this case, it has the value 2. Now, if we take the English language as an example, it has two plural forms: singular and plural. Therefore, our rules look like this:
- If the counter has the integer value of 1, use the singular: “rabbit.”
- If the counter has a value that is not equal to 1, use the plural: “rabbits.”
However, the same isn’t true in Polish, where the same word—“rabbit,” or “królik”—can take more than two forms:
- If the counter has the integer value of 1, use “królik.”
- If the counter has a value that ends in 2–4, excluding 12–14, use “królika.”
- If the counter is not 1 and has a value that ends in either 0 or 1, or the counter ends in 5–9, or the counter ends in 12–14, use “królików.”
- If the counter has any other value than the above, use “króliki.”
So much for “singular” and “plural.” For languages with three or more plural forms, we need more specific labels.
Different languages use different types of numbers#section3
You may also want to display the counter along with the pluralized noun, such as, “You have 3 rabbits.” However, not all languages use the Arabic numbers you may be accustomed to—for example, Arabic uses Arabic Indic numbers, ٠١٢٣٤٥٦٧٨٩:
- 0 books: ٠ كتاب
- 1 book: كتاب
- 3 books: ٣ كتب
- 11 books: ١١ كتابًا
- 100 books: ١٠٠ كتاب
Different languages or regions use different number formats#section4
We also often aim to make large numbers more readable by adding separators, as when we render the number 1000 as “1,000” in English. But many languages and regions use different fractional and thousand separators. For example, German renders the number 1000 as “1.000.” Other languages don’t group numbers by thousands, but rather by tens of thousands.
Solution: ICU’s MessageFormat#section5
Pluralization is a complex problem to solve—at least, if you want to handle all these edge cases. Recently, International Components for Unicode (ICU) did precisely that with MessageFormat. ICU’s MessageFormat is a markup language specifically tailored to localization. It allows you to define, in a declarative way, how nouns should be rendered in various plural forms. It sorts all the plural forms and rules for you, and formats numbers correctly. Unfortunately, many of you probably haven’t heard of MessageFormat yet, because it’s mostly used by people who work specifically with internationalization—known to insiders as i18n—and JavaScript has only recently evolved to handle it.
Let’s talk about how it works.
Using CLDR for plural forms#section6
CLDR stands for Common Locale Data Repository, and it’s a repo that companies like Google, IBM, and Apple draw on to get information about number, date, and time formatting. CLDR also contains data on the plural forms and rules for many languages. It’s probably the largest locale data repository in the world, which makes it ideal as the basis for any internationalization JavaScript tool.
CLDR defines up to six different plural forms. Each form is assigned a name: zero, one, two, few, many, or other. Not all locales need every form; remember, English only has two: one and other. The name of each form is based on its corresponding plural rule. Here is a CLDR example for the Polish language—a slightly altered version of our earlier counter rules:
- If the counter has the integer value of 1, use the plural form one.
- If the counter has a value that ends in 2–4, excluding 12–14, use the plural form few.
- If the counter is not 1 and has a value that ends in either 0 or 1, or the counter ends in 5–9, or the counter ends in 12–14, use the plural form many.
- If the counter has any other value than the above, use the plural form other.
Instead of manually implementing CLDR plural forms, you can make use of tools and libraries. For example, I created L10ns, which compiles the code for you; Yahoo’s FormatJS has all the plural forms built in. The big benefits of these tools and libraries are that they scale well, as they abstract the plural-form handling. If you choose to hard-code these plural forms yourself, you will end up exhausting yourself and your teammates, because you’ll need to keep track of all the forms and rules, and define them over and over whenever and wherever you want to format a plural string.
MessageFormat#section7
MessageFormat is a domain-specific language that uses CLDR, and is specifically tailored for localizing strings. You define markup inline. For example, we want to format the message “I have X rabbit[s]” using the right plural word for “rabbit”:
var message = 'I have {rabbits, plural, one{# rabbit} other{# rabbits}}';
As you can see, a plural format is defined inside curly brackets {}. It takes a counter, rabbits, as the first argument. The second argument defines which type of formatting. The third argument includes CLDR’s plural form (one, many). You need to define a sub-message inside the curly brackets that corresponds to each plural form. You can also pass in the symbol # to render the counter with the correct number format and numbering system, so it will solve the problems we identified earlier with the Arabic Indic numbering system and with number formatting.
Here we parse the message in the en-US locale and output different messages depending on which plural form the variable rabbits takes:
var message = 'I have {rabbits, plural, one{# rabbit} other{# rabbits}}.';
var messageFormat = new MessageFormat('en-US');
var output = messageFormat.parse(message);
// Will output "I have 1 rabbit."
console.log(output({ rabbits: 1 }));
// Will output "I have 10 rabbits."
console.log(output({ rabbits: 10 }));
Benefits of inlining#section8
As you can see in the preceding message, we defined a plural format inline. If it weren’t inlined, we might need to repeat the words “I have…” for all plural forms, instead of just typing them once. Imagine if you needed to use even more words, as in the following example:
{
one: 'My name is Emily and I got 1 like in my latest post.'
other: 'My name is Emily and I got # likes in my latest post.'
}
Without inlining, we’d need to repeat “My name is Emily and I got…in my latest post” every single time. That’s a lot of words.
In contrast, inlining in ICU’s MessageFormat simplifies things. Instead of repeating the phrase for every plural form, all we need to do is localize the word “like”:
var message = 'My name is Emily and I got {likes, plural, one{# like} other{# likes}} in my latest post';
Here we don’t need to repeat the words “My name is Emily and I got…in my latest post” for every plural form. Instead, we can simply localize the word “like.”
Benefits of nesting messages#section9
MessageFormat’s nested nature also helps us by giving us endless possibilities to define a multitude of complex strings. Here we define a select format in a plural format to demonstrate how flexible MessageFormat is:
var message = '{likeRange, select,\
range1{I got no likes}\
range2{I got {likes, plural, one{# like} other{# likes}}}\
other{I got too many likes}\
}';
A select format matches a set of cases and, depending on which case it matches, it outputs the corresponding sub-message. And it is perfect to construct range-based messages. In the preceding example, we want to construct three kinds of messages for each like range. As you can see in range2, we defined a plural format to format the message “I got X like[s],” and then nested the plural format inside a select format. This example showcases a very complex formatting that very few syntaxes can achieve, demonstrating MessageFormat’s flexibility.
With the above format, here are the messages we can expect to get:
- “I got no likes,” if
likeRangeis inrange1. - “I got 1 like,” if
likeRangeis inrange2and the number of likes is 1. - “I got 10 likes,” if
likeRangeis inrange2and the number of likes is 10. - “I got too many likes,” if
likeRangeis in neitherrange1norrange2.
These are very hard concepts to localize—even one of the most popular internationalization tools, gettext, can’t do this.
Storage and pre-compiled messages#section10
However, instead of storing MessageFormat messages in a JavaScript variable, you might want to use some kind of storage format, such as multiple JSON files. This will allow you to pre-compile the messages to simple localization getters. If you don’t want to handle this alone, you might try L10ns, which handles storage and pre-compilation for you, as well as syncing translation keys between source and storage.
Do translators need to know MessageFormat?#section11
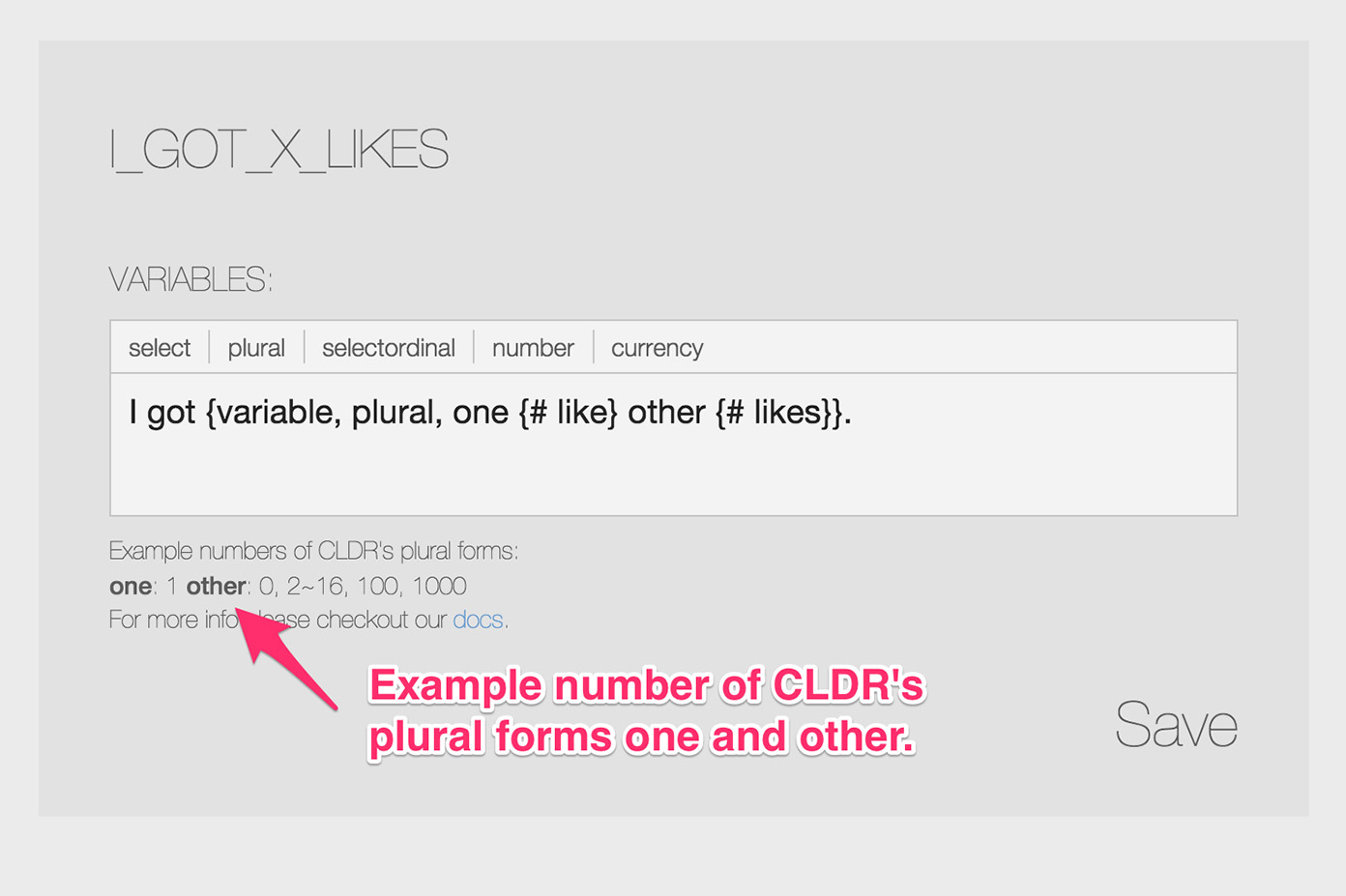
You might think it would be too overwhelming for non-programming translators to know Messageformat and CLDR’s plural form. But in my experience, teaching them the basics of how the markup looks and what it does, and what CLDR’s plural forms are, takes just a few minutes and provides enough information for translators to do their job using MessageFormat. L10ns’ web interface also displays the example numbers for each CLDR plural form for easy reference.
Pluralization isn’t easy—but it’s worth it#section12
Yes, pluralization has a lot of edge cases that aren’t easily solvable. But ICU’s MessageFormat has helped me tremendously in my work, giving me endless flexibility to translate plural strings. As we move to a more connected world, localizing applications to more languages and regions is a must-do. Knowledge about general localization problems and tools to solve them are must-haves. We need to localize apps because the world is more connected, but we can also localize apps to help make the world more connected.
Actually, in Polish we speak:
If the counter has the integer value of 1, use “królik”
If the counter has a value that ends in 2–4, excluding 12–14, use “króliki”
If the counter is not 1 and has a value that ends in either 0 or 1, or the counter ends in 5–9, or the counter ends in 12–14, use “królików”
And we use “królika” only and always when there are fractals involved ex. 2.5 “królika”.
Great article!
great insights on internationalisation challenges!
@Michal thanks for pointing that out. “króliki” and “królika” should change place. The fractionals part becomes part of “other”, so there is nothing wrong there. I want to use other, because it reflects the CLDR plural form’s “other”.
A small mistake from my side.
@gibran thanks
Great that you touched on the subject of pluralization. For me, the workarounds for that, such as “Number of books: #” and “# Book(s) available” is a clear indicator of lazy engineering. I’m looking at you, Facebook.
Luckily, the situation has been improving in recent years, thanks in part to standarization.
@Maciej I guess you were lazy because there weren’t any good solution out there? Now, you can keep being lazy, but instead of doing wrong — you can do right.
Oh, no no, I’ve never been lazy about this – I used to create my own solutions for this problem. The thing is, many developers didn’t care, but recently, as you said, they can keep not caring and use the tools available. 😉
@Michał 21 “królików”? Shouldn’t it be 21 “króliki”?
IIRC, the rules for Polish are rather:
If the counter has the integer value of 1, use “królik” (nominative singular)
If the counter is not 1 and has a value that ends in 1–4, excluding 11–14, use “króliki” (nominative plural)
If the counter ends in 0 or 5–9, or the counter ends in 11–14, use “królików” (genitive plural)
2.5 “królika” (genitive singular), if you read 2.5 as “two and a half”. If you read “two point five” it’s “królików” (genitive plural).
A little different in Russian:
If the counter has a value that ends in 1, excluding 11, use “кролик” (nominative plural)
If the counter has a value that ends in 2–4, excluding 12–14, use “кролика” (genitive singular)
If the counter ends in 0 or 5–9, or the counter ends in 11–14, use “кроликов” (genitive plural)
No, see http://unicode.org/repos/cldr-tmp/trunk/diff/supplemental/language_plural_rules.html#pl
– one (1) królik
– few (n mod 10 in 2..4 and n mod 100 not in 12..14) króliki
– many (n is not 1 and n mod 10 in 0..1 or n mod 10 in 5..9 or n mod 100 in 12..14) królików
– other (everything else like fractals) królika
@stef I’m glad that you referred to the CLDR source. In my article, I’m using those formulas. Though slightly expressed in more common spoken words than mathematical formulas.
@stef It’s 21 królików, genitive plural. I stand corrected.
My Polish got a little rusty, needs some polishing.
Kto to wymyślił?
Com certeza nós não falantes do inglês, seremos beneficiados
I think it would be nice to see the actual internationalization string for polish rabbits. How do you specify when to write królik, króliki, królików and królika with that system ?
Also take a look at the open-source library “iLib” which implements plurals (and much more) in pure Javascript based on the CLDR rules. You can get it and use it for free at http://sourceforge.net/projects/i18nlib/
Thanks Tingan, for a great article!
It’s a good thing to use MessageFormat, but sometimes it could be overcomplicated for simpler use cases, like pluralizing a single word in an E-Mail or something.
With this in mind, I’ve created a very simple JavaScript library that can be used to pluralize words in almost any language. It also uses CLDR database for multiple locales support. It’s API is very minimalistic and integration is extremely simple. It’s called Numerous.
I’ve also written a small introduction article to it: «How to pluralize any word in different languages using JavaScript?».
I will be glad to hear your feedback on it!
Cheers!