Amo i dati. Adoro anche JavaScript. Tuttavia, i dati e il codice JavaScript lato client sono spesso considerati mutualmente esclusivi. In genere, il settore considera l’elaborazione e l’aggregazione dei dati come una funzione di back-end, mentre JavaScript è solo per la visualizzazione dei dati pre-aggregati. La larghezza di banda e il tempo di elaborazione sono visti come enormi colli di bottiglia per gestire i dati sul lato client. E, per la maggior parte, sono d’accordo. Ma ci sono situazioni in cui l’elaborazione dei dati nel browser ha perfettamente senso. In quei casi d’uso, come possiamo avere successo?
Pensare ai dati#section1
Lavorare con i dati in JavaScript richiede sia dati completi sia una comprensione degli strumenti che abbiamo a disposizione senza dover effettuare inutili chiamate server. Facciamo un’utile distinzione tra dati trilaterali e dati riepilogati.
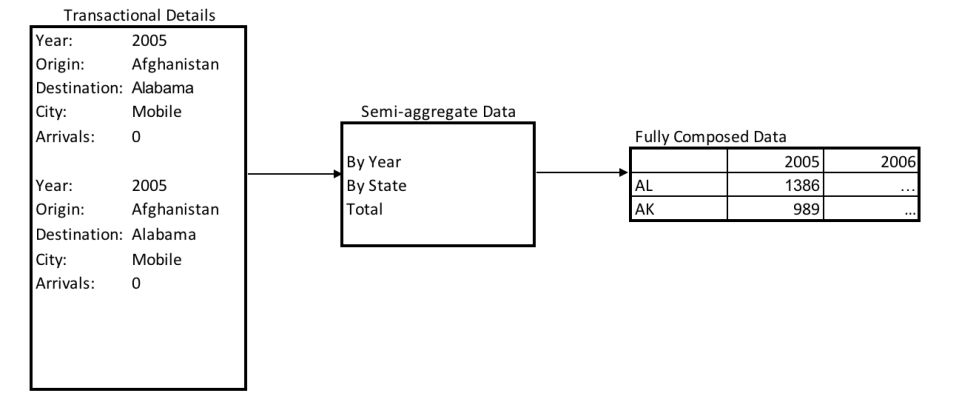
I dati trilaterali sono costituiti da dati transazionali raw (ossia dati ricavati direttamente da una transazione, non elaborati). Si tratta del dettaglio di basso livello che, di per sé, è quasi impossibile da analizzare. Dall’altra parte dello spettro abbiamo i dati riepilogati. Si tratta di dati che possono essere presentati in un modo significativo e ragionato. Chiameremo questi i nostri dati composti. La cosa più importante per gli sviluppatori sono le strutture dati che risiedono tra i nostri dettagli transazionali e i nostri dati completamente composti. Questo è il nostro “punto giusto”. Tali set di dati sono aggregati ma contengono più di quello che ci serve per la presentazione finale. Sono multidimensionali in quanto hanno due o più dimensioni diverse (e più misure) che offrono flessibilità per la presentazione dei dati. Questi set di dati consentono agli utenti finali di modellare i dati ed estrarre le informazioni per ulteriori analisi. Sono piccoli e performanti, ma offrono abbastanza dettagli per consentire approfondimenti che voi, come autori, potreste non aver previsto.
Non è necessario che l’obiettivo sia di avere i dati in forma perfetta per evitare tutte le manipolazioni nel front end. Al contrario, fate sì che i dati siano ridotti a un dataset multidimensionale. Definite diverse dimensioni chiave (es., persone, prodotti, luoghi e tempo) e misure (ad es. somma, conteggio, media, minimo e massimo) a cui potrebbe essere interessato il vostro cliente. Infine, presentate i dati sulla pagina con elementi di form che possano suddividere i dati in un modo che permetta un’analisi più approfondita.
Nella creazione dei dataset abbiamo a che fare con un equilibrio delicato. Dovrete avere sufficienti dati per rendere le vostre statistiche significative senza mettere troppo sotto stress la macchina client. Questo significa trovare dei requisiti chiari e concisi. A seconda di quanto è grande il dataset, potreste aver bisogno di includere molte dimensioni e metodi di misura differenti. Alcune cose da tenere a mente:
- La varietà del contenuto è un caso limite o qualcosa di frequente? Seguite la regola 80/20: generalmente, all’80% degli utenti serve il 20% di ciò che è disponibile.
- Ogni dimensione è finita? Le dimensioni dovrebbero sempre avere un insieme predeterminato di valori. Per esempio, un inventario di prodotti sempre in aumento potrebbe essere travolgente, mentre le categorie di prodotto potrebbero funzionare bene.
- Quando è possibile, aggregate i dati, specialmente le date. Se potete cavarvela aggregando per anni, fatelo. Se dovete scendere al trimestre o al mese, potete farlo, ma evitate qualunque cosa al di sotto di questo.
- Less is more. Una dimensione che ha meno valori è migliore per la performance. Per esempio, prendete un dataset con 200 righe. Se aggiungete un’altra dimensione che ha quattro possibili valori, crescerà al massimo di 200 * 4 = 800 righe. Se aggiungete una dimensione che ha 50 valori, crescerà di 200 * 50 = 10.000 righe. Ciò sarà aggravato da ogni dimensione che aggiungete.
- Nei set di dati multidimensionali, evitare di riepilogare le misure che devono essere ricalcolate ogni volta che cambia il set di dati. Per esempio, se pianificate di mostrare le medie, dovreste includere il totale e la somma. Calcolate le medie dinamicamente. In questo modo, se riepilogate i dati, potete ricalcolare le medie usando i valori riassunti.
Assicuratevi di comprendere i dati con cui state lavorando prima di cercare di fare una qualsiasi delle cose elencate sopra. Potreste formulare delle ipotesi sbagliate che portano a decisioni malinformate. La qualità dei dati è sempre una priorità assoluta. Questo vale per i dati che state interrogando e producendo.
Non prendete mai un dataset e formulate ipotesi su una dimensione o una misura. Non esitare a chiedere i data dictionaries o altra documentazione sui dati per aiutarvi a capire che cosa state guardando. L’analisi dei dati non è qualcosa che si indovina. Potrebbero essere state applicate regole aziendali oppure i dati potrebbero essere filtrati preventivamente. Se non avete davanti a voi queste informazioni, potreste facilmente finire per comporre set di dati e visualizzazioni che sono prive di significato o, peggio ancora, completamente fuorvianti.
Il seguente esempio di codice vi aiuterà a spiegare ciò ulteriormente. Il codice completo per questo esempio può essere trovato su GitHub.
Il nostro use case#section2
Per il nostro esempio useremo il dataset di BuzzFeed da “Where U.S. Refugees Come From—and Go—in Charts”. Creeremo una piccola app che ci mostrerà il numero di rifugiati arrivati in uno stato selezionato in un anno selezionato. Nello specifico mostreremo uno dei seguenti casi a seconda della richiesta dell’utente:
- arrivi totali per uno stato in un dato anno;
- arrivi totali per tutti gli anni per un dato stato;
- arrivi totali per tutti gli stati in un dato anno.
La UI per selezionare stato e anno sarà una semplice form:
Il codice:
- Manderà una richiesta per i dati.
- Convertirà i risultati in JSON.
- Processerà i dati.
- Farà il log di qualsiasi errore nella console. (Nota: per essere sicuri che lo step 3 non venga eseguito fino a che non sarà completamente recuperato il dataset, useremo il metodo then e faremo tutto il processing dei dati all’interno di quel blocco.)
- Mostrerà i risultati all’utente.
Non vogliamo passare dei dataset eccessivamente larghi ai browser per due ragioni principali: ampiezza di banda e CPU. Al contrario, aggregheremo i dati sul server con Node.js.
Dati sorgente:
[{"year":2005,"origin":"Afghanistan","dest_state":"Alabama","dest_city":"Mobile","arrivals":0},
{"year":2006,"origin":"Afghanistan","dest_state":"Alabama","dest_city":"Mobile","arrivals":0},
... ]Dati multidimensionali:
[{"year": 2005, "state": "Alabama","total": 1386},
{"year": 2005, "state": "Alaska", "total": 989},
... ]
Come sistemare la struttura dati#section3
AJAX e la Fetch API#section4
C’è una serie di modi in JavaScript per raccogliere dati da una sorgente esterna. Storicamente, avreste usato una XHR request. XHR è ampiamente supportata, ma è anche piuttosto complessa e richiede molti metodi differenti. Ci sono anche librerie come Axios o la AJAX API di jQuery. Queste possono essere utili per ridurre la complessità e forniscono il supporto cross-browser. Potrebbero essere un’opzione se state giù usando queste librerie, ma noi vogliamo optare per una soluzione nativa ovunque sia possibile. Infine, c’è la più recente Fetch API. È meno supportata, ma è semplice e concatenabile. E se state usando un transpiler (es., Babel), convertirà il vostro codice in un equivalente molto più supportato.
Per il nostro use case, useremo la Fetch API per mettere i dati nella nostra applicazione:
window.fetchData = window.fetchData || {};
fetch('./data/aggregate.json')
.then(response => {
// when the fetch executes we will convert the response
// to json format and pass it to .then()
return response.json();
}).then(jsonData => {
// take the resulting dataset and assign to a global object
window.fetchData.jsonData = jsonData;
}).catch(err => {
console.log("Fetch process failed", err);
});Questo codice è una snippet tratta da main.js nel repo GitHub.
Il metodo fetch() invia una richiesta per i dati e noi convertiamo i risultati in JSON. Per assicurarci che lo statement seguente non vada in esecuzione fino a dopo aver completato il retrieve dell’intero dataset, usiamo il metodo then() e facciamo tutto il nostro data processing all’interno di quel blocco. Da ultimo, usiamo console.log() per loggare tutti gli errori.
Il nostro obiettivo, qui, è di identificare le dimension chiave che ci servono per fare i report – anno e stato – prima di aggregare il numero di arrivi per quelle dimension, rimuovendo il paese di origine e la città di destinazione. Potete far riferimento allo script di Node.js /preprocess/index.js sul repo GitHub per maggiori dettagli su come farlo. Genera il file aggregate.json caricato da fetch() sopra.
Dati multidimensionali#section5
L’obiettivo della formattazione multidimensionale è la flessibilità: i dati sono sufficientemente dettagliati da far sì che l’utente non debba inviare una query al server ogni volta che desidera rispondere a una domanda diversa, ma riepilogati in modo tale che l’applicazione non debba procedere rapidamente all’interno dell’intero dataset con ogni nuovo pezzo di dati. È necessario anticipare le domande e fornire dati che formulino le risposte. I clienti vogliono essere in grado di fare qualche analisi senza sentirsi costretti o completamente sopraffatti.
Come per la maggior parte delle API, lavoreremo con i dati JSON. JSON è uno standard che viene usato dalla maggior parte delle API per mandare dati alle applicazioni sotto forma di oggetti costituiti da coppie nome-valore. Prima di tornare al nostro use case, diamo un’occhiata a un esempio di dataset multidimensionale:
const ds = [{
"year": 2005,
"state": "Alabama",
"total": 1386,
"priorYear": 1201
}, {
"year": 2005,
"state": "Alaska",
"total": 811,
"priorYear": 1541
}, {
"year": 2006,
"state": "Alabama",
"total": 989,
"priorYear": 1386
}];Con il nostro dataset aggregato in maniera appropriata, possiamo usare JavaScript per analizzarlo ulteriormente. Diamo un’occhiata ad alcuni metodi nativi per gli array per comporre i dati.With your dataset properly aggregated, we can use JavaScript to further analyze it. Let’s take a look at some of JavaScript’s native array methods for composing data.
Come lavorare efficacemente con i dati via JavaScript#section6
Array.filter()#section7
Il metodo filter() del prototype Array (Array.prototype.filter()) prende una funzione che testa ogni item nell’array, ritornando un altro array che contiene solo i valori che hanno passato il test. Vi permette di creare dei sottoinsiemi significativi di dati basati su una selezione dropdown o dei filtri testuali. Supponendo che abbiate incluso dimensioni significative e discrete per il vostro dataset multidimensionale, il vostro utente sarà in grado di ricavare delle opinioni guardando delle tranche individuali di dati.
ds.filter(d => d.state === "Alabama");
// Result
[{
state: "Alabama",
total: 1386,
year: 2005,
priorYear: 1201
},{
state: "Alabama",
total: 989,
year: 2006,
priorYear: 1386
}]Array.map()#section8
Il metodo map() del prototype Array (Array.prototype.map()) prende una funzione e ci fa passare ogni item dell’array, ritornando un nuovo array con un egual numero di elementi. Mappare i dati vi dò l’abilità di creare dei dataset collegati. Uno use case per questo è mappare dati ambigui a dati più significativi e descrittivi. Un’altro è di prendere delle metriche e farci dei calcoli per permettere un’analisi più approfondita.
Use case n.1—mappare i dati a dati più significativi:
ds.map(d => (d.state.indexOf("Alaska")) ? "Contiguous US" : "Continental US");
// Result
[
"Contiguous US",
"Continental US",
"Contiguous US"
]Use case n.2—mappare i dati ai risultati calcolati:
ds.map(d => Math.round(((d.priorYear - d.total) / d.total) * 100));
// Result
[-13, 56, 40]Array.reduce()#section9
Il metodo reduce() del prototype Array (Array.prototype.reduce()) prende una funzione e ci fa girare ogni item dell’array, ritornando un risultato aggregato. È usato più comunemente per fare matematica, come aggiungere o moltiplicare ogni numero in un array, sebbene possa anche essere usato per concatenare stringhe o fare molte altre cose. L’ho sempre trovato un po’ complicato: lo si impara meglio con un esempio.
Quando presenterete i dati, dovrete essere sicuri che siano riassunti in maniera da dare degli insight ai vostri utenti. Anche se avete fatto dei riassunti a livello generale dei dati lato server, qui è dove permettete un’aggregazione ulteriore, basata sui bisogni specifici del consumatore. Per la nostra app, vogliamo aggiungere il totale a ogni entry e mostrare il risultato aggregato. Lo faremo usando reduce() per iterare in ogni record e per aggiungere il valore corrente all’accumulatore. Il risultato finale sarà la somma di tutti i valori (totale) per l’array.
ds.reduce((accumulator, currentValue) =>
accumulator + currentValue.total, 0);
// Result
3364Applicare queste funzioni al nostro use case#section10
Una volta che avremo i nostri dati, assegneremo un evento al pulsante “Get the Data” che presenterà il sottoinsieme appropriato dei nostri dati. Ricordate che abbiamo molte centinaia di item nei nostri dati JSON. Il codice per legare i dati al nostro pulsante si trova nel nostro main.js:
document.getElementById("submitBtn").onclick =
function(e){
e.preventDefault();
let state = document.getElementById("stateInput").value || "All"
let year = document.getElementById("yearInput").value || "All"
let subset = window.fetchData.filterData(year, state);
if (subset.length == 0 )
subset.push({'state': 'N/A', 'year': 'N/A', 'total': 'N/A'})
document.getElementById("output").innerHTML =
`<table class="table">
<thead>
<tr>
<th scope="col">State</th>
<th scope="col">Year</th>
<th scope="col">Arrivals</th>
</tr>
</thead>
<tbody>
<tr>
<td>${subset[0].state}</td>
<td>${subset[0].year}</td>
<td>${subset[0].total}</td>
</tr>
</tbody>
</table>`
}
Se lasciate vuoto lo stato o l’anno, quel campo andrà di default a “All”. Il seguente codice è disponibile in /js/main.js. Dovreste osservare la funzione filterData(), che è dove teniamo la porzione più grossa delle funzionalità di aggregazione e filtering.
// with our data returned from our fetch call, we are going to
// filter the data on the values entered in the text boxes
fetchData.filterData = function(yr, state) {
// if "All" is entered for the year, we will filter on state
// and reduce the years to get a total of all years
if (yr === "All") {
let total = this.jsonData.filter(
// return all the data where state
// is equal to the input box
dState => (dState.state === state)
.reduce((accumulator, currentValue) => {
// aggregate the totals for every row that has
// the matched value
return accumulator + currentValue.total;
}, 0);
return [{'year': 'All', 'state': state, 'total': total}];
}
...
// if a specific year and state are supplied, simply
// return the filtered subset for year and state based
// on the supplied values by chaining the two function
// calls together
let subset = this.jsonData.filter(dYr => dYr.year === yr)
.filter(dSt => dSt.state === state);
return subset;
};
// code that displays the data in the HTML table follows this. See main.js.Quando uno stato o un anno è vuoto, andrà di default a “All” e filtreremo il nostro dataset a quella particolare dimension e riassumeremo la metrica per tutte le righe in quella dimension. Quando verranno inseriti sia anno sia stato, filtreremo semplicemente i valori.
Abbiamo ora un esempio funzionante in cui:
- partiamo con un dataset raw, transazionale,
- creiamo un dataset semi-aggregato, multidimensionale,
- e costruiamo dinamicamente un risultato completamente composto.
Si noti che una volta che i dati vengono estratti dal client, possiamo manipolarli in un certo numero di modi diversi senza dover effettuare chiamate successive al server. Questo è particolarmente utile perché se l’utente perde la connettività, non perde la capacità di manipolare i dati. Ciò è utile se si sta creando una progressive web app (PWA) che deve essere disponibile offline. (Se non siete sicuri se la vostra app web debba essere una PWA, questo articolo può aiutare.)
Una volta ottenuto il controllo completo su questi tre metodi, è possibile creare praticamente qualsiasi analisi desiderata su un set di dati. Mappare una dimensione nel set di dati in una categoria più ampia e riepilogare utilizzando reduce. Combinato con una libreria come D3, potete mappare questi dati in grafici e diagrammi per consentire una visualizzazione dei dati completamente personalizzabile.
Conclusioni#section11
Questo articolo dà un’idea migliore di ciò che è possibile in JavaScript quando si lavora con i dati. Come ho accennato, JavaScript lato client non è in alcun modo un sostituto per la traduzione e la trasformazione dei dati sul server, dove dovrebbe essere fatto il lavoro pesante. Ma allo stesso tempo, non dovrebbe essere completamente escluso quando i dataset vengono trattati in maniera appropriata.
Nessun commento
Hai qualcosa da dire?
Abbiamo disattivato i commenti, ma puoi vedere quello che gli altri hanno detto prima che li disattivassimo.
Altro da ALA
Webwaste
Uno strumento essenziale per catturare i vostri progressi lavorativi
Andiamo al cuore dell’accessibilità digitale
JavaScript Responsabile, Parte II
JavaScript Responsabile: parte prima