
Nota degli editori: Siamo lieti di condividere un estratto dal Chapter 5 del nuovo libro di Mat Marquis, JavaScript for Web Designers, disponibile ora presso A Book Apart.
Prima di fare qualunque cosa con una pagina, voi ed io dobbiamo parlare di qualcosa di molto importante: il Document Object Model. Ci sono due scopi per il DOM: fornire a JavaScript una mappa di tutti gli elementi sulla nostra pagina e darci un insieme di metodi per accedere a questi elementi, ai loro attributi e al loro contenuto.
Tuttavia, la parte “object” di Document Object Model dovrebbe avere molto più senso adesso che quando è apparso il DOM per la prima volta: il DOM è una rappresentazione di una pagina web sotto forma di un oggetto, composto da proprietà che rappresentano ciascuna gli elementi figlio del documento e sotto-proprietà che rappresentano ciascuno degli elementi figlio di quegli elementi figlio, e così via. Sono oggetti fino in fondo.
window: il Global Context#section1
Tutto quello che facciamo con JavaScript ricade all’interno dello scope di un singolo oggetto: window. L’oggetto window rappresenta, in maniera piuttosto intuibile, l’intera finestra del browser. Contiene l’intero DOM, così come – e questa è la parte delicata – l’intero JavaScript.
Quando abbiamo parlato per la prima volta di scope delle variabili, abbiamo sfiorato il concetto dell’esistenza di uno scope “globale” e di uno “locale”, il che significa che una variabile può essere disponibile o in tutte le parti dei nostri script o solo nelle funzioni in cui sono incluse.
L’oggetto window è quello scope globale. Tutte le funzioni e metodi creati in JavaScript sono creati a partire dall’oggetto window. Non dobbiamo far riferimento a window costantemente, ovviamente, o l’avreste visto spesso prima di adesso, dal momento che window è lo scope globale, JavaScript controlla window per ogni variabile che non abbiamo definito noi stessi. In effetti, l’oggetto console, che spero adesso conosciate e amiate, è un metodo dell’oggetto window:
window.console.log
function log() { [native code] }È difficile visualizzare le variabili con scope globale o locale prima di conoscere window, ma è molto più semplice dopo: quando introduciamo una variabile nello scope globale, la stiamo rendendo una proprietà di window e, dal momento che non dobbiamo esplicitamente referenziare window ogni volta che accediamo ad una delle sue proprietà o metodi, possiamo chiamare quella variabile ovunque nei nostri script usando semplicemente il suo identificatore. Quando accediamo a un identificatore, questo è quello che stiamo in realtà facendo:
function ourFunction() { var localVar = "I’m local."; globalVar = "I’m global."; return "I’m global too!"; };undefinedwindow.ourFunction();I’m global too!window.localVar;undefinedwindow.globalVar;I’m global.
L’intera rappresentazione della pagina del DOM è una proprietà di window: nello specifico, window.document. Scrivere semplicemente window.document nella developer console ritorna tutto il markup della pagina attuale in una stringa enorme, il che non è particolarmente utile, ma si può accedere a tutto sulla pagina come sotto-proprietà di window.document nello stesso identico modo. Ricordatevi che non dobbiamo specificare window per accedere alla proprietà del document: window è unico nel suo genere, dopo tutto.
document.head
<head>...</head>
document.body
<body>...</body>Quelle due proprietà sono esse stesse oggetti che contengono proprietà che sono oggetti e così via. (“In un certo senso, tutto è un oggetto”).
Usare il DOM#section2
Gli oggetti in window.document costituiscono la mappa del documento di JavaScript, ma non è molto utile per noi, perlomeno non quando stai cercando di accedere ai nodi DOM nel modo in cui accederesti ad ogni altro oggetto. Muoverci manualmente attraverso l’oggetto document sarebbe per noi un gran mal di testa e per questo motivo i nostri script cadrebbero completamente a pezzi non appena cambia un qualsiasi pezzo nel markup.
Tuttavia, window.document non è una semplice rappresentazione della pagina: ci fornisce anche una API più smart per accedere a quelle informazioni. Per esempio, se vogliamo trovare ogni elemento p sulla pagina, non dobbiamo scrivere una stringa di property keys, ma usare un metodo helper presente all’interno di document che li riunisce tutti quanti per noi in un elenco simile ad un array. Aprite un qualunque sito di vostra scelta, purché sia probabile che abbia almeno uno o due elementi paragrafo al suo interno e provate questo nella vostra console:
document.getElementsByTagName( "p" );
[<p>...</p>, <p>...</p>, <p>...</p>, <p>...</p>]Dal momento che abbiamo a che fare dei tipi di dati così familiari, abbiamo già una mezza idea di come lavorare con loro:
var paragraphs = document.getElementsByTagName( "p" );
undefined
paragraphs.length
4
paragraphs[ 0 ];
<p>...</p>I metodi DOM però non ci ritornano degli array in senso stretto. Metodi come getElementsByTagName ritornano “liste di nodi” che si comportano in maniera molto simile agli array. Ogni item in una nodeList fa riferimento a un singolo nodo nel DOM, come un p o un div e ha un numero di metodi specifici del DOM “built-in”. Per esempio, il metodo innerHTML ritorna qualsiasi markup contenga un nodo (elementi, testo e così via) come una stringa:
var paragraphs = document.getElementsByTagName( "p" ), lastIndex = paragraphs.length – 1,/* Use the length of the `paragraphs`
node list minus 1 (because of zero-indexing)
to get the last paragraph on the page */ lastParagraph = paragraphs[ lastIndex ]; lastParagraph.innerHTML; And that’s how I spent my summer vacation.
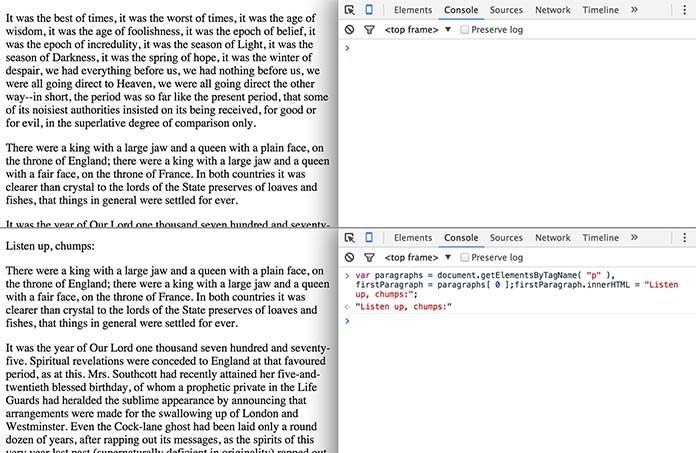
Fig 5.1: Le prime bozze sono sempre difficili.
Nello stesso modo in cui questi metodi ci danno accesso alle informazioni sulla pagina resa, così ci permettono anche di alterare quell’informazione. Per esempio, il metodo innerHTML fa questo nello stesso modo in cui cambieremmo il valore di un qualsiasi altro oggetto: con un semplice segno di uguale seguito dal nuovo valore.
var paragraphs = document.getElementsByTagName( "p" ),
firstParagraph = paragraphs[ 0 ];
firstParagraph.innerHTML = "Listen up, chumps:";
"Listen up, chumps:"La mappa del DOM di JavaScript funziona in entrambe le direzioni: document viene aggiornato ogni volta che cambia il markup e il nostro markup viene aggiornato ogniqualvolta qualcosa cambia all’interno di document (Fig 5.1).
In maniera simile, la DOM API ci fornisce un certo numero di metodi per creare, aggiungere e rimuovere elementi. Sono tutti sillabati in inglese corrente, perciò, anche se possono sembrare un po’ verbosi, non sono troppo difficili da scomporre.
DOM Scripting#section3
Prima di cominciare, abbandoniamo la developer console per un attimo. Secoli fa, abbiamo costruito passo passo un template HTML molto basilare che richiama uno script remoto e adesso ne rivedremo le impostazioni. Con la conoscenza che avete acquisito finora su JavaScript e con l’introduzione al DOM, abbiamo finito di dire alla console di ripeterci le cose come un pappagallo: è ora di creare qualcosa.
Aggiungeremo un “taglio” a una pagina index piena di testo: un paragrafo con un’anteprima seguito da un link per mostrare l’intero testo. Però non faremo navigare l’utente verso un’altra pagina, ma, al contrario, useremo JavaScript per mostrare l’intero testo sulla stessa pagina.
Cominciamo con l’impostare un documento HTML che si collega ad un foglio di stile esterno e ad un file esterno dello script, nulla di che. Entrambe i files, lo stylesheet e lo script, sono per ora vuoti e hanno le estensioni .css e .js. Mi piace tenere i miei CSS in una sotto-directory /css e i miei JavaScript in una sotto-directory /js, ma siete liberi di fare come preferite.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<link rel="stylesheet" type="text/css" href="css/style.css">
</head>
<body>
<script src="js/script.js"></script>
</body>
</html>Popoleremo quella pagina con svariati paragrafi di testo. Un qualunque pezzo di testo che trovate in giro va bene, incluso, con le mie scuse per i content strategist tra il pubblico, il buon vecchio lorem ipsum. Stiamo semplicemente simulando una rapida pagina per un articolo, come un blog post.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<link rel="stylesheet" type="text/css" href="css/style.css">
</head>
<body>
<h1>JavaScript for Web Designers</h1>
<p>In all fairness, I should start this book with an
apology—not to you, reader, though I don’t doubt that
I’ll owe you at least one by the time we get to the
end. I owe JavaScript a number of apologies for the
things I’ve said to it during the early years of my
career, some of which were strong enough to etch glass.</p>
<p>This is my not-so-subtle way of saying that JavaScript
can be a tricky thing to learn.</p>
[ … ]
<script src="js/script.js"></script>
</body>
</html>Siete liberi di aprire lo stylesheet e giocare con la tipografia, ma non distraetevi troppo. Dovremo scrivere un po’ di CSS più tardi, ma adesso abbiamo dello scripting da fare.
Possiamo suddividere questo script in qualche task discreto: dobbiamo aggiungere un link “Read More” al primo paragrafo, dobbiamo nascondere tutti gli elementi p tranne il primo e dobbiamo mostrare quegli elementi nascosti quando l’utente interagisce con il link ”Read More”.
Cominceremo con l’aggiungere il link ”Read More” alla fine del primo paragrafo. Aprite il vostro file script.js ancora vuoto ed inserite quanto segue:
var newLink = document.createElement( "a" );Innanzitutto, stiamo inizializzando la variabile newLink, che usa document.createElement( "a" ) per – proprio come dice sulla confezione – creare un nuovo elemento a. Questo elemento non esiste ancora da nessuna parte: per far sì che appaia sulla pagina dovremo aggiungerlo manualmente. Ancora prima però, <a></a> senza alcun attributo o contenuto non è molto utile. Prima di aggiungerlo alla pagina, popoliamolo con tutte le informazioni di cui ha bisogno.
Potremmo fare questo dopo aver aggiunto il link al DOM, ovviamente, ma non ha senso fare molteplici aggiornamenti all’elemento sulla pagina invece che un aggiornamento che aggiunga il risultato finale: fare tutto il lavoro su quell’elemento prima di metterlo nella pagina ci aiuta a mantenere il nostro codice prevedibile.
Fare un singolo viaggio nel DOM quando è possibile è inoltre migliore per la performance, ma è facile essere ossessionati dalle micro-ottimizzazioni della performance. Come avete visto, JavaScript offre frequentemente più modi per fare la stessa cosa e uno di questi metodi potrebbe tecnicamente avere prestazioni migliori dell’altro. Questo porta invariabilmente a codice “eccessivamente intelligente”, loop complicati che richiedono spiegazioni di persona perché abbiano senso, semplicemente per limare dei preziosi picosecondi al tempo di caricamento. L’ho fatto, mi sorprendo ancora a farlo, ma voi non dovreste provarci. Quindi, mentre fare quanti meno andirivieni dal DOM possibili è una buona abitudine da crearsi per il bene della performance, la ragione principale è che mantiene il nostro codice leggibile e prevedibile. Facendo dei viaggi al DOM solo quando ne abbiamo davvero bisogno, evitiamo di ripeterci e rendiamo più ovvi i nostri punti di interazione con il DOM per i futuri maintainer dei nostri script.
Ok. Torniamo al nostro <a></a> vuoto e senza attributi che fluttua nell’etere di JavaScript, totalmente indipendente dal nostro documento.
Ora possiamo usare due altre interfacce DOM per rendere quel link più utile: setAttribute per assegnargli gli attributi e innerHTML per popolarlo con del testo. Questi hanno una sintassi leggermente differente. Possiamo semplicemente assegnare una stringa usando innerHTML, nel modo in cui assegneremmo un valore ad ogni altro oggetto. D’altro canto, setAttribute si aspetta due argomenti: l’attributo e il valore che vogliamo assegnare a quell’attributo, in questo ordine. Dal momento che non pianifichiamo nessuna destinazione per il nostro link, imposteremo solo un cancelletto (hash) come href, un link alla pagina su cui ci troviamo già.
var newLink = document.createElement( "a" );
newLink.setAttribute( "href", "#" );
newLink.innerHTML = "Read more";Avrete notato che stiamo usando queste interfacce nel nostro riferimento memorizzato all’elemento invece che a document stesso. Tutti i nodi del DOM hanno accesso ai metodi come quelli che stiamo usando qui, usiamo document.getElementsByTagName( "p" ) solamente perché vogliamo ottenere tutti gli elementi paragrafo nel documento. Se solo volessimo ottenere tutti gli elementi paragrafo all’interno di un certo div, potremmo fare la stessa cosa con una reference a quel div, qualcosa come ourSpecificDiv.getElementsByTagName( "p" );. E dal momento che vogliamo impostare l’attributo href e l’HTML interno del link che abbiamo creato, facciamo riferimento a queste proprietà usando newLink.setAttribute e newLink.innerHTML.
Poi: vogliamo che questo link appaia alla fine del nostro primo paragrafo, quindi il nostro script avrà bisogno di un modo per far riferimento a quel primo paragrafo. Sappiamo già che document.getElementsByTagName( "p" ) ci dà una node list di tutti i paragrafi nella pagina. Dal momento che le node list si comportano come array, possiamo far riferimento al primo item nella node list uno usando l’indice 0.
var newLink = document.createElement( "a" );
var allParagraphs = document.getElementsByTagName( "p" );
var firstParagraph = allParagraphs[ 0 ];
newLink.setAttribute( "href", "#" );
newLink.innerHTML = "Read more";Per mantenere il nostro codice leggibile, è una buona idea inizializzare le nostre variabili in cima allo script, anche solo inizializzandole a undefined (assegnandogli un identificatore ma nessun valore), se pianifichiamo di assegnarli un valore in seguito. In questo modo conosciamo tutti gli identificatori in gioco.
Quindi, adesso abbiamo tutto quello che ci serve per appendere un link alla fine del primo paragrafo: l’elemento che vogliamo appendere (newLink) e l’elemento che vogliamo appendergli (firstParagraph).
Uno dei metodi built-in su tutti i nodi del DOM è appendChild, che, come suggerisce il nome, ci permette di appendere un elemento figlio a quel nodo del DOM. Chiameremo quindi il metodo appendChild sulla nostra reference salvata al primo paragrafo nel documento, passandogli newLink come argomento.
var newLink = document.createElement( "a" );
var allParagraphs = document.getElementsByTagName( "p" );
var firstParagraph = allParagraphs[ 0 ];
newLink.setAttribute( "href", "#" );
newLink.innerHTML = "Read more";
firstParagraph.appendChild( newLink );Ora, finalmente, abbiamo qualcosa a cui poter puntare quando ricarichiamo la pagina. Se tutto è andato secondo il nostro piano, adesso dovremmo avere un link ”Read more” alla fine del primo paragrafo sulla pagina. Se tutto non è andato secondo i piani – a causa di un punto e virgola messo male o di parentesi non accoppiate, per esempio – la developer console vi avviserà che qualcosa è andato storto, quindi assicuratevi di tenerla aperta.
Ci siamo quasi, ma non è troppo bello: il nostro link è appiccicato al paragrafo che lo precede, dal momento che il link è display: inline di default (Fig 5.2).

Fig 5.2: Beh, è un inizio.
Abbiamo un paio di opzioni per gestire questa cosa: non entrerò nei dettagli di tutte le varie sintassi qui, ma il DOM vi dà anche accesso alle informazioni di stile degli elementi, sebbene, nella sua forma più basica, ci permette solo di leggere e cambiare le informazioni di stile associate all’attributo style. Giusto per capire un attimo come funziona, cambiamo il link a display: inline-block e aggiungiamo alcuni pixel di margine nel lato sinistro, così che non collida con il nostro testo. Proprio come l’impostazione degli attributi, lo faremo prima di aggiungere il link alla pagina:
var newLink = document.createElement( "a" );
var allParagraphs = document.getElementsByTagName( "p" );
var firstParagraph = allParagraphs[ 0 ];
newLink.setAttribute( "href", "#" );
newLink.innerHTML = "Read more";
newLink.style.display = "inline-block";
newLink.style.marginLeft = "10px";
firstParagraph.appendChild( newLink );Bene, aggiungere quelle righe ha funzionato, ma non senza un paio di inghippi. Per prima cosa, parliamo della sintassi (Fig 5.3).

Fig 5.3: Adesso si ragiona.
Ricordate che gli identificatori non possono contenere trattini e, dal momento che tutto è una (specie) di oggetto, il DOM fa anche riferimento agli stili nel formato a oggetto. Ogni proprietà CSS che contenga un trattino diventa invece “camel-cased”: margin-left diventa marginLeft, border-radius-top-left diventa borderRadiusTopLeft e così via. Tuttavia, dal momento che il valore che impostiamo per queste proprietà è una stringa, i trattini vanno bene. Un po’ strano e un’altra cosa da ricordare, ma è tutto piuttosto gestibile, di sicuro non una ragione per evitare di assegnare stili in JavaScript, se la situazione lo rende assolutamente necessario.
Una ragione migliore per evitare gli stili in JavaScript è di mantenere una separazione tra comportamento e presentazione. JavaScript è il nostro “behavioral” layer nel modo in cui il CSS è il nostro “presentational” layer e spesso i due si devono incontrare. Cambiare stili su una pagina non dovrebbe significare cercare qualcosa riga dopo riga di funzioni e variabili, così come non vorremmo seppellire gli stili nel nostro markup. Le persone che potrebbero finire a mantenere gli stili del sito potrebbero non essere completamente a loro agio ad editare JavaScript e, dal momento che cambiare gli stili in JavaScript significa che stiamo indirettamente aggiungendo stili con l’attributo style, qualsiasi cosa scriviamo in uno script, di default sovrascriverà i contenuti di un foglio di stile.
Possiamo mantenere questa separazione di interessi usando invece di nuovo setAttribute per dare al nostro link una classe. Quindi, eliminiamo quelle due righe con gli stili e aggiungiamone una al loro posto che imposti la classe.
var newLink = document.createElement( "a" );
var allParagraphs = document.getElementsByTagName( "p" );
var firstParagraph = allParagraphs[ 0 ];
newLink.setAttribute( "href", "#" );
newLink.setAttribute( "class", "more-link" );
newLink.innerHTML = "Read more";
firstParagraph.appendChild( newLink );Adesso possiamo assegnare degli stili a .more-link nel nostro foglio di stile come al solito:
.more-link {
display: inline-block;
margin-left: 10px;
}Molto meglio (Fig 5.4). Conviene tenere a mente, per il futuro, che usare setAttribute in questo modo su un nodo nel DOM significa sovrascrivere qualsiasi classe sia già presente sull’elemento, ma questo non è un problema quando si mette insieme un elemento da zero.

Fig 5.4: Nessun cambiamento visibile, ma questo cambiamento mantiene le decisioni di stile nel CSS e le decisioni sul comportamento in JavaScript.
Ora siamo pronti a spostarci sul secondo item della nostra to do list: nascondere tutti gli altri paragrafi.
Poiché abbiamo fatto dei cambiamenti a del codice che sappiamo che funzionava già, assicuratevi di ricaricare la pagina per essere sicuri che tutto funzioni ancora secondo le aspettative. Non vogliamo introdurre un bug qui e continuare a scrivere codice, o alla fine ci impantaneremo in tutti i cambiamenti che abbiamo fatto. Se tutto è andato secondo i piani, la pagina dovrebbe risultare uguale quando adesso la ricarichiamo.
Adesso abbiamo una lista di tutti i paragrafi sulla pagina e abbiamo bisogno di agire su ciascuno di essi. Abbiamo bisogno di un loop e, dal momento che stiamo iterando su una node list simile a un array, abbiamo bisogno di un ciclo for. Giusto per essere sicuri che il loop funzioni correttamente, facciamo un log di ogni paragrafo nella console prima di procedere:
var newLink = document.createElement( "a" );
var allParagraphs = document.getElementsByTagName( "p" );
var firstParagraph = allParagraphs[ 0 ];
newLink.setAttribute( "href", "#" );
newLink.setAttribute( "class", "more-link" );
newLink.innerHTML = "Read more";
for( var i = 0; i < allParagraphs.length; i++ ) {
console.log( allParagraphs[ i ] );
}
firstParagraph.appendChild( newLink );Il vostro link Read More dovrebbe ancora essere nel primo paragrafo come al solito e la vostra console dovrebbe essere piena di testo di riempimento (Fig 5.5).

Fig 5.5: Sembra che il nostro loop si stia comportando a dovere.
Adesso dobbiamo nascondere quei paragrafi con display: none e abbiamo un paio di opzioni: potremmo usare una class nel modo in cui abbiamo fatto prima, ma non sarebbe un’idea terribile usare gli stili in JavaScript per questo scopo. Stiamo controllando tutto il meccanismo mostra e nascondi dal nostro script e non accadrà mai che vorremo questo comportamento sovrascritto da qualcosa in un foglio di stile. In questo caso, ha senso usare i metodi built-in del DOM per applicare gli stili:
var newLink = document.createElement( "a" );
var allParagraphs = document.getElementsByTagName( "p" );
var firstParagraph = allParagraphs[ 0 ];
newLink.setAttribute( "href", "#" );
newLink.setAttribute( "class", "more-link" );
newLink.innerHTML = "Read more";
for( var i = 0; i < allParagraphs.length; i++ ) {
allParagraphs[ i ].style.display = "none";
}
firstParagraph.appendChild( newLink );Se adesso ricarichiamo la pagina, sarà tutto sparito: il nostro JavaScript fa un loop in tutta la lista di paragrafi e li nasconde tutti. Dobbiamo fare un’eccezione per il primo paragrafo e questo significa logica condizionale, una dichiarazione if e la variabile i ci dà un valore semplice con cui controllare:
var newLink = document.createElement( "a" );
var allParagraphs = document.getElementsByTagName( "p" );
var firstParagraph = allParagraphs[ 0 ];
newLink.setAttribute( "href", "#" );
newLink.setAttribute( "class", "more-link" );
newLink.innerHTML = "Read more";
for( var i = 0; i < allParagraphs.length; i++ ) {
if( i === 0 ) {
continue;
}
allParagraphs[ i ].style.display = "none";
}
firstParagraph.appendChild( newLink );Se questa è la prima volta nel loop, la parola chiave continue salta il resto dell’iterazione corrente e poi, a differenza di usare break, il loop continua verso l’iterazione seguente.
Se adesso ricaricate la pagina, avremo un solo paragrafo con un link ”Read More” alla fine, ma tutti gli altri saranno nascosti. Fin qui tutto bene e, se non avete ottenuto lo stesso risultato, controllate attentamente la console per essere sicuri che non manchi nulla.
Ora che avete una solida base nel DOM, andiamo davvero a fondo per vedere dove ci porta.
Vuoi saperne di più?#section4
Il resto di questo capitolo (oltre a quello che avete appena letto) va ancora più nel dettaglio ed è solo un capitolo della guida pratica di Mat per aiutarvi con il vostro attuale progetto. Date un’occhiata a JavaScript for Web Designers su A Book Apart.
Nessun commento
Altro da ALA
Webwaste
Uno strumento essenziale per catturare i vostri progressi lavorativi
Andiamo al cuore dell’accessibilità digitale
JavaScript Responsabile, Parte II
JavaScript Responsabile: parte prima